📌 相关文章
- 改善ML模型的性能
- 改善ML模型的性能(1)
- 性能 javascript (1)
- PHP 7-性能
- Java 9-尝试改善资源(1)
- Java 9-尝试改善资源
- 性能 javascript 代码示例
- 网络性能
- 网络性能(1)
- 如何在 r 中进行预测 (1)
- 性能测试(1)
- 性能测试 (1)
- 性能测试
- 性能测试
- 性能测试(1)
- Magento 2中的性能分析和数据库性能
- Magento 2中的性能分析和数据库性能(1)
- javascript 性能 - Javascript (1)
- 链接预测——使用 Networkx 预测网络中的边缘
- javascript 性能 - Javascript 代码示例
- 改善软件经济学|套装2
- 改善软件经济学|套装2(1)
- Tableau-预测(1)
- Tableau 中的预测
- Tableau 中的预测(1)
- Tableau-预测
- 预测试概率 (1)
- 改善大学安置的技巧(1)
- 改善大学安置的技巧
📜 改善预测性能
📅 最后修改于: 2021-01-23 05:53:32 🧑 作者: Mango
在本章中,我们将着重于构建一个模型,该模型利用其中包含的许多属性来帮助预测学生的表现。重点是显示学生在考试中的失败结果。
处理
评估的目标值为G3。此值可以归类,并进一步分为失败和成功。如果G3值大于或等于10,则学生通过考试。
例
考虑下面的示例,如果学生遇到以下情况,则执行代码以预测性能-
import pandas as pd
""" Read data file as DataFrame """
df = pd.read_csv("student-mat.csv", sep=";")
""" Import ML helpers """
from sklearn.preprocessing import LabelEncoder
from sklearn.model_selection import train_test_split
from sklearn.metrics import confusion_matrix
from sklearn.model_selection import GridSearchCV, cross_val_score
from sklearn.pipeline import Pipeline
from sklearn.feature_selection import SelectKBest, chi2
from sklearn.svm import LinearSVC # Support Vector Machine Classifier model
""" Split Data into Training and Testing Sets """
def split_data(X, Y):
return train_test_split(X, Y, test_size=0.2, random_state=17)
""" Confusion Matrix """
def confuse(y_true, y_pred):
cm = confusion_matrix(y_true=y_true, y_pred=y_pred)
# print("\nConfusion Matrix: \n", cm)
fpr(cm)
ffr(cm)
""" False Pass Rate """
def fpr(confusion_matrix):
fp = confusion_matrix[0][1]
tf = confusion_matrix[0][0]
rate = float(fp) / (fp + tf)
print("False Pass Rate: ", rate)
""" False Fail Rate """
def ffr(confusion_matrix):
ff = confusion_matrix[1][0]
tp = confusion_matrix[1][1]
rate = float(ff) / (ff + tp)
print("False Fail Rate: ", rate)
return rate
""" Train Model and Print Score """
def train_and_score(X, y):
X_train, X_test, y_train, y_test = split_data(X, y)
clf = Pipeline([
('reduce_dim', SelectKBest(chi2, k=2)),
('train', LinearSVC(C=100))
])
scores = cross_val_score(clf, X_train, y_train, cv=5, n_jobs=2)
print("Mean Model Accuracy:", np.array(scores).mean())
clf.fit(X_train, y_train)
confuse(y_test, clf.predict(X_test))
print()
""" Main Program """
def main():
print("\nStudent Performance Prediction")
# For each feature, encode to categorical values
class_le = LabelEncoder()
for column in df[["school", "sex", "address", "famsize", "Pstatus", "Mjob",
"Fjob", "reason", "guardian", "schoolsup", "famsup", "paid", "activities",
"nursery", "higher", "internet", "romantic"]].columns:
df[column] = class_le.fit_transform(df[column].values)
# Encode G1, G2, G3 as pass or fail binary values
for i, row in df.iterrows():
if row["G1"] >= 10:
df["G1"][i] = 1
else:
df["G1"][i] = 0
if row["G2"] >= 10:
df["G2"][i] = 1
else:
df["G2"][i] = 0
if row["G3"] >= 10:
df["G3"][i] = 1
else:
df["G3"][i] = 0
# Target values are G3
y = df.pop("G3")
# Feature set is remaining features
X = df
print("\n\nModel Accuracy Knowing G1 & G2 Scores")
print("=====================================")
train_and_score(X, y)
# Remove grade report 2
X.drop(["G2"], axis = 1, inplace=True)
print("\n\nModel Accuracy Knowing Only G1 Score")
print("=====================================")
train_and_score(X, y)
# Remove grade report 1
X.drop(["G1"], axis=1, inplace=True)
print("\n\nModel Accuracy Without Knowing Scores")
print("=====================================")
train_and_score(X, y)
main()
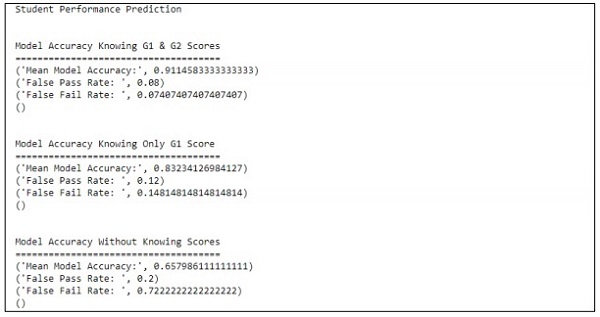
输出
上面的代码生成如下所示的输出
仅参考一个变量来处理预测。参考一个变量,学生成绩预测如下所示-