📌 相关文章
- 敏捷数据科学-敏捷的实现(1)
- 敏捷数据科学-敏捷的实现
- 敏捷数据科学-数据科学过程
- 敏捷数据科学-数据科学过程(1)
- 敏捷数据科学教程
- 敏捷数据科学教程(1)
- 讨论敏捷数据科学
- 讨论敏捷数据科学(1)
- Python数据科学简介
- Python数据科学简介(1)
- 敏捷数据科学-数据可视化(1)
- 敏捷数据科学-数据可视化
- 敏捷数据科学-敏捷中的数据处理(1)
- 敏捷数据科学-敏捷中的数据处理
- 敏捷数据科学-有用的资源
- 敏捷数据科学-有用的资源(1)
- 敏捷数据科学-数据丰富(1)
- 敏捷数据科学-数据丰富
- 敏捷数据科学-SQL与NoSQL(1)
- 敏捷数据科学-SQL与NoSQL
- 敏捷数据科学-处理报告(1)
- 敏捷数据科学-处理报告
- 敏捷数据科学-预测的作用(1)
- 敏捷数据科学-预测的作用
- 数据科学中的 R 与Python(1)
- 数据科学用Python
- 数据科学用Python(1)
- 数据科学用Python
- 数据科学中的 R 与Python
📜 敏捷数据科学-简介
📅 最后修改于: 2021-01-23 05:47:50 🧑 作者: Mango
敏捷数据科学是一种将数据科学与敏捷方法一起用于Web应用程序开发的方法。它关注于适合于组织变革的数据科学过程的输出。数据科学包括构建应用程序,这些应用程序通过分析,交互式可视化以及现在应用的机器学习来描述研究过程。
敏捷数据科学的主要目标是-
记录并指导解释性数据分析,以发现并遵循引人注目的产品的关键路径。
敏捷数据科学的组织遵循以下原则-
连续迭代
此过程涉及使用创建表,图表,报告和预测进行连续迭代。建立预测模型将需要特征工程的许多迭代,包括提取和产生洞察力。
中间输出
这是生成的输出的跟踪列表。甚至有人说失败的实验也有结果。跟踪每个迭代的输出将有助于在下一个迭代中创建更好的输出。
原型实验
原型实验涉及根据实验分配任务并生成输出。在给定的任务中,我们必须进行迭代以获取洞察力,而这些迭代可以最好地解释为实验。
数据整合
软件开发生命周期包括不同阶段,其数据对于-
-
顾客
-
开发人员,以及
-
这生意
数据集成为更好的前景和产出铺平了道路。
金字塔数据值
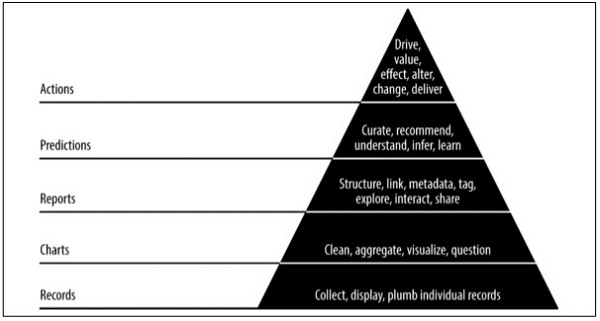
上面的金字塔值描述了“敏捷数据科学”开发所需的层次。它从根据需求收集记录开始,然后收集各个记录。图表是在清理和汇总数据后创建的。汇总的数据可用于数据可视化。使用适当的结构,元数据和数据标签生成报告。从顶部开始的金字塔的第二层包括预测分析。预测层是在其中创造更多价值的地方,但有助于创建专注于要素工程的良好预测。
最顶层涉及有效驱动数据价值的操作。这种实现方式的最好例证是“人工智能”。