📌 相关文章
- Python |如何以及在哪里应用特征缩放?
- Python |如何以及在哪里应用特征缩放?(1)
- python代码示例中的特征缩放
- 特征缩放——第 3 部分(1)
- 特征缩放——第 3 部分
- 归一化和非归一化的区别(1)
- 归一化和非归一化的区别
- 归一化和非归一化的区别
- 归一化和非归一化的区别
- 归一化和非归一化的区别(1)
- 在数据框中缩放特征的函数 - Python (1)
- 在数据框中缩放特征的函数 - Python 代码示例
- python 函数来缩放数据框 pandas 中的选定特征 - Python (1)
- python 函数来缩放数据框 pandas 中的选定特征 - Python 代码示例
- python 归一化相关 - Python (1)
- 缩放 - Python (1)
- python 归一化相关 - Python 代码示例
- Python|小数归一化()方法
- Python|小数归一化()方法(1)
- 归一化的优缺点
- 归一化的优缺点(1)
- 归一化的优缺点
- 归一化的优缺点(1)
- 缩放 - Python 代码示例
- 最小-最大归一化的问题
- 最小-最大归一化的问题(1)
- PHP 7 |特征
- PHP 7 |特征
- PHP 7 |特征(1)
📜 Python | 如何以及在哪里应用特征缩放/归一化
📅 最后修改于: 2020-04-28 04:56:19 🧑 作者: Mango
特征缩放或归一化:这是数据预处理的步骤,适用于数据的独立变量或特征。从根本上说,它有助于标准化特定范围内的数据。有时,它也有助于加快算法的计算速度。
使用的包:
sklearn.preprocessing导入:
from sklearn.preprocessing import StandardScaler后端
标准化中使用的公式将值替换为其Z分数。

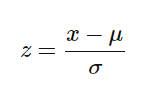
通常,“ 拟合”方法用于特征缩放
fit(X, y = None)
计算均值和std以用于以后的缩放.
import pandas as pd
from sklearn.preprocessing import StandardScaler
# 从CSV读取数据
data = read_csv('芒果文档.csv')
data.head()
# 初始化scaler
scaler = StandardScaler()
# 缩放数据
scaler.fit(data)为什么以及在何处应用特征缩放?
现实世界的数据集包含的特征在大小、单位和范围上都有很大差异。当要素的比例尺不相关或具有误导性时,应执行归一化;而当比例尺有意义时,则不应进行归一化。使用欧几里得距离度量的算法对绝对值敏感。在这里,特征缩放有助于平均权衡所有特征。
正式地,如果数据集中的某个要素比其他要素具有更大的比例,则在测量欧几里得距离的算法中,这个大规模的要素将成为主导并且需要进行标准化。
特征缩放很重要的算法示例
1. K-Means在这里使用欧几里得距离来衡量特征缩放。
2. K-Nearest-Neighbours也需要特征缩放。
3. 主成分分析(PCA):尝试获得具有最大方差的特征,这里也需要特征缩放。
4. 梯度下降:随着特征缩放后Theta计算变得更快,计算速度也随之提高。
注意:朴素贝叶斯,线性判别分析和基于树的模型不受特征缩放的影响。
简而言之,任何不是基于距离的算法都不会受到要素缩放的影响。