📌 相关文章
- 编译器设计中的解析树(1)
- 编译器设计中的解析树(1)
- 编译器设计中的解析树
- 编译器设计中的解析树
- 编译器设计中的解析树
- 编译器设计中的解析树(1)
- 编译器设计中的解析器类型(1)
- 编译器设计中的解析器类型(1)
- 编译器设计中的解析器类型
- 编译器设计中的解析器类型
- 编译器设计中的增量编译器(1)
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器
- 编译器设计中的增量编译器(1)
- 编译器设计教程
- 编译器设计教程(1)
- 编译器设计-正则表达式(1)
- 编译器设计-正则表达式
- 编译器解析树和语法树(1)
- 编译器解析树和语法树
- 讨论编译器设计
- 编译器设计中的左递归 (1)
- 编译器设计-概述(1)
- 编译器设计-概述
- 编译器设计介绍
- 编译器设计介绍
- 编译器设计介绍(1)
- 编译器设计介绍(1)
- 编译器设计-体系结构
📜 编译器设计-解析类型
📅 最后修改于: 2021-01-18 05:26:05 🧑 作者: Mango
语法分析器遵循通过上下文无关语法定义的生产规则。生产规则的实现方式(派生)将解析分为两种类型:自顶向下解析和自底向上解析。
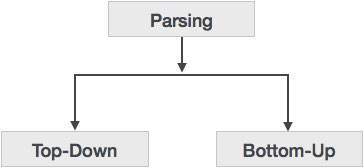
自顶向下解析
当解析器开始从起始符号构造解析树,然后尝试将起始符号转换为输入时,称为自顶向下解析。
-
递归下降解析:这是自顶向下解析的一种常见形式。之所以称为递归,是因为它使用递归过程来处理输入。递归下降解析遭受回溯。
-
回溯:这意味着,如果一个产品的派生失败,则语法分析器将使用同一产品的不同规则重新启动该过程。此技术可能会多次处理输入字符串,以确定正确的产量。
自下而上的解析
顾名思义,自下而上的解析从输入符号开始,然后尝试构造解析树直到起始符号。
例:
输入字符串:a + b * c
生产规则:
S → E
E → E + T
E → E * T
E → T
T → id
让我们开始自下而上的解析
a + b * c
读取输入,并检查是否有任何生产与输入匹配:
a + b * c
T + b * c
E + b * c
E + T * c
E * c
E * T
E
S