计算 Pandas DataFrame 中项集的频率
在本文中,我们将解释如何计算 Pandas 中给定 DataFrame 中项集的频率。使用 count()、size() 方法、Series.value_counts() 和 pandas.Index.value_counts() 方法,我们可以计算给定 DataFrame 中项集的频率数。在这里,我们将解释如何在实践中使用这些功能的几个示例。
原始数据:

示例 1:
使用Series.value_counts():此方法适用于 pandas.Series 对象。由于每个 DataFrame 对象都是 Series 对象的集合,因此我们可以应用此方法来获取一列中值的频率计数。
Python3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujrat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujrat', 'Jammu', 'Kolkata', 'Bihar']
})
count = df['A'].value_counts()
display(count)
count = df['B'].value_counts()
display(count)Python3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujrat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujrat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A']).size()
display(freq)
freq = df.groupby(['B']).size()
display(freq)Python3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujrat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujrat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A'])['B'].agg('count').reset_index()
display(freq)
freq = df.groupby(['B'])['A'].agg('count').reset_index()
display(freq)Python3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujrat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujrat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A']).count()
display(freq)
freq = df.groupby(['B']).count()
display(freq)输出:
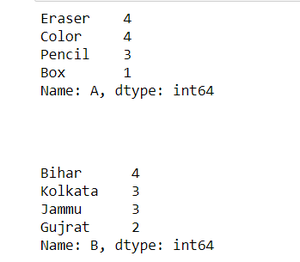
示例 2:使用Pandas dataframe.size()
它返回元素的总数,通过将 shape 方法返回的行和列相乘进行比较。
蟒蛇3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujrat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujrat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A']).size()
display(freq)
freq = df.groupby(['B']).size()
display(freq)
输出:
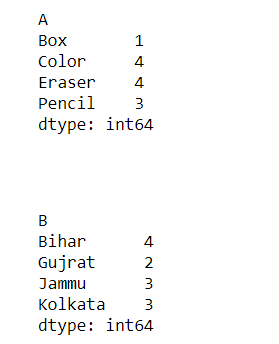
示例 3:使用Pandas reset_index()
它是一种重置数据帧索引的方法。 reset_index() 方法将范围从 0 到数据长度的整数列表设置为索引。
蟒蛇3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujrat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujrat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A'])['B'].agg('count').reset_index()
display(freq)
freq = df.groupby(['B'])['A'].agg('count').reset_index()
display(freq)
输出:

示例 4:使用Pandas dataframe.count()
它用于计算编号。给定轴上的非 NA/null 观测值。它也适用于非浮动类型的数据。
蟒蛇3
import pandas as pd
df = pd.DataFrame({
'A': ['Box', 'Color', 'Pencil', 'Eraser',
'Color', 'Pencil', 'Eraser', 'Color',
'Color', 'Eraser', 'Eraser', 'Pencil'],
'B': ['Jammu', 'Kolkata', 'Bihar', 'Gujrat',
'Kolkata', 'Bihar', 'Jammu', 'Bihar',
'Gujrat', 'Jammu', 'Kolkata', 'Bihar']
})
freq = df.groupby(['A']).count()
display(freq)
freq = df.groupby(['B']).count()
display(freq)
输出:
