- SAS数据集
- SAS数据集(1)
- SAS宏(1)
- SAS宏
- 如何将数据导入SAS?
- 如何将数据导入SAS?(1)
- 在SAS中写入数据集
- 在SAS中写入数据集(1)
- 在SAS中格式化数据集
- SAS函数(1)
- SAS函数
- SAS字符串(1)
- SAS字符串
- SAS-SQL
- SAS-SQL(1)
- 合并数据框 - Python (1)
- sas - 任何代码示例
- 如何合并 R 中的数据帧?(1)
- 如何合并 R 中的数据帧?
- SAS循环
- SAS循环(1)
- SAS变量(1)
- SAS变量
- 合并数据框 - Python 代码示例
- SAS应用程序(1)
- SAS应用程序
- r 如何合并数据框 - Python (1)
- SAS教程
- SAS教程(1)
📅 最后修改于: 2021-01-08 14:13:14 🧑 作者: Mango
SAS-合并数据集
加盟|结合
在上一主题中,我们学习了SAS中的多个变量排序,并看到可以同时基于多个变量对数据值进行排序。现在,我们将学习如何以SAS编程语言合并数据集。您会发现许多示例,以加深了解。
因此,让我们开始….
什么是SAS合并?
SAS中的合并是一个合并来自两个或多个SAS数据集的观察值的过程。合并的基础是,合并数据集必须具有一个内部具有公共数据值(或观测值)的公共变量。
使用以下步骤合并数据集:
- 创建一个新的数据集进行合并。
- 我们使用By语句表示公共变量的名称,该公共变量用于匹配合并的先决条件。
- 在数据集名称之前使用MERGE语句。
- 合并数据集必须至少具有一个公共变量。
例如:
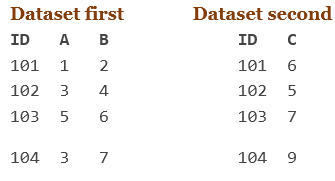
正如您在上面看到的,ID是两个数据集中的公共变量。
使用以下语法来合并第一和第二数据集:
DATASET third;
merge first second;
By id;
run;
输出:
ID A B C
101 1 2 6
102 3 4 5
103 5 6 7
104 3 7 9
在上面的示例中,两个数据集已合并。两个数据集包含不同的数据,并且变量ID包含相同的数据,因为它是唯一标识符(无重复)。
让我们通过一个例子来理解:
当我们使用merge语句合并两个数据集时,并且我们已经知道,对一个公共变量的每次观察在另一个数据集中都有一个匹配项,那么我们可以非常直接地合并。这是一个例子。
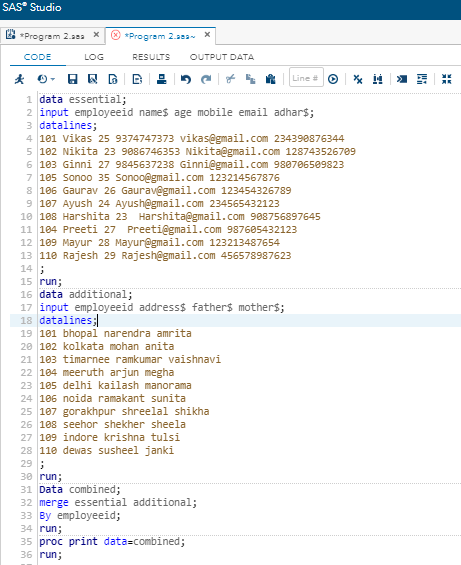
通常,在相同情况下,不同的数据存储在两个或多个单独的数据集中。例如,我们要存储员工的数据,为此我们创建了两个数据集,一个是必不可少的,另一个是附加的。基本数据集包含员工的非常基本的信息,例如工作ID,姓名,手机,电子邮件,adhar等,而其他数据集则包含很少使用的信息。
必要数据
data essential;
input employeeid name$ age mobile email adhar$;
datalines;
101 Vikas 25 9374747373 vikas@gmail.com 234390876344
102 Nikita 23 9086746353 Nikita@gmail.com 128743526709
103 Ginni 27 9845637238 Ginni@gmail.com 980706509823
105 Sonoo 35 Sonoo@gmail.com 123214567876
106 Gaurav 26 Gaurav@gmail.com 123454326789
107 Ayush 24 Ayush@gmail.com 234565432123
108 Harshita 23 Harshita@gmail.com 908756897645
104 Preeti 27 Preeti@gmail.com 987605432123
109 Mayur 28 Mayur@gmail.com 123213487654
110 Rajesh 29 Rajesh@gmail.com 456578987623
;
run;
数据集附加
data additional;
input employeeid address$ father$ mother$;
datalines;
101 bhopal narendra amrita
102 kolkata mohan anita
103 timarnee ramkumar vaishnavi
104 meeruth arjun megha
105 delhi kailash manorama
106 noida ramakant sunita
107 gorakhpur shreelal shikha
108 seehor shekher sheela
109 indore krishna tulsi
110 dewas susheel janki
;
run;
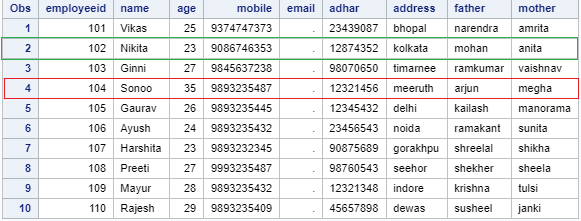
现在,创建“合并的”新数据集以合并基本数据集和其他数据集。
Data combined;
merge essential additional;
By employeeid;
run;
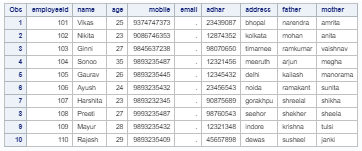
proc print data=combined;
run;
现在,在SAS studio中执行此代码。
输出:
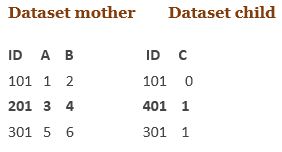
当匹配不完美时
如果变量是公用的,但数据集之间的数据值不公用,会发生什么?
例如:
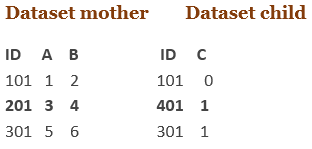
在数据集母级中,第二观察值(ID = 201)与数据集子级中的第二观察值(ID = 401)不匹配。匹配合并将如下所示:
Data third;
merge first second;
by id;
run;
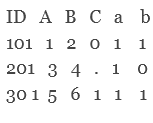
结果
ID A B C
101 1 2 0 both data sets are contributing to this observation
201 3 4 . only data set first contributed to this observation
301 5 6 1 both data sets contributed to this observation
让我们通过一个例子来理解:
在这里,我们使用上面提到的示例,但是更改了它的一些数据值。取两个数据集;一个是必不可少的,另一个是附加的。现在,我们在附加数据集中更改了两个变量ID的数据值,让我们看看结果如何。
在SAS Studio中执行此代码
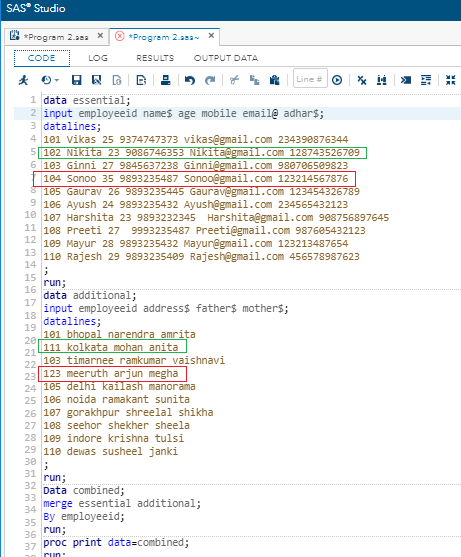
输出:
在上面的代码中,您可以看到,变量ID在基本数据集和附加数据集中都是通用的,但是变量ID的两个数据值(在图像中突出显示,一个由绿色突出显示,另一个由红色突出显示)在数据集“附加”中发生了变化。
当我们在SAS Studio中执行此代码时,它将根据数据集“基本”中提到的数据值生成输出(请考虑输出图像),但是如果在日志窗口中进行检查,则会看到错误消息。
IN =变量
如果只想将合并输出放入数据集中,该怎么办?仅表示两个输入数据集均在其中起作用的那些观测值。
换句话说,当您不想打印没有贡献的观测值时,请使用IN = Variables。
SAS已经为您安装了特殊的临时变量,称为“ IN =变量”,以便您可以执行更多操作。
现在,您要做的是:
1.将多余的变量与merge语句一起用于两个合并数据集
句法
merge mother (in=a) child (in=b); /* x & y are your choices of names */
2.在数据步骤中,适当使用“ IN =变量”。
让我们通过一个例子来理解:
Data other;
1. merge mother (in=a) child (in=b); /* a & b are your choices of names */
2. by id;
3. if a=1 and b=1;
4. run;
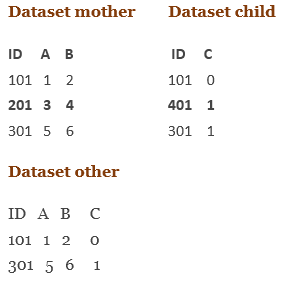
我们可以在输出中看到;数据集other仅保留匹配ID的数据值。
- 如果我们只想保留贡献观测值,则将值1赋给变量a和b。
- 如果我们只想保留不起作用的观测值,则给变量a和b赋0。
在上面的示例中,“ IN =变量” A和B的值如下:
如果不仅要保留匹配的数据值,而且还要跟踪不匹配的数据值的不同数据集,则可以通过以下方式创建三个数据集:
1. data other /* other, other1, other2 are your choices of data set names */
2. other1
3. other2;
4. merge one(in= a) two(in= b);
5. by id;
6. if a = 1 & b = 1 then output other; /* write all matches to other */
7. if a = 1 & b = 0 then output other1;
8. if a = 0 and b = 1 then outputother2;
9. run;
概要
因此,这全部与合并数据集有关。在本节中,我们了解了什么是SAS合并数据集,如何合并两个或多个数据集以及在数据集不匹配时会发生什么。
希望您清楚地理解了该主题。但是,如果您仍然有任何问题,请在我们的联系方式部分中询问。