- Python | 使用pandas.read_csv()读取csv(1)
- Python|使用 pandas.read_csv() 读取 csv
- pandas 读取 csv 块 - Python (1)
- pandas 读取 csv - Python (1)
- 使用 pandas read csv 存储为字符串的读取列表 - Python (1)
- pandas 读取 csv - Python 代码示例
- pandas 读取 csv 块 - Python 代码示例
- 使用 pandas read csv 存储为字符串的读取列表 - Python 代码示例
- 在 R 编程中读取 CSV 文件的内容 – read.csv()函数
- 在 R 编程中读取 CSV 文件的内容 – read.csv()函数(1)
- 读取csv python(1)
- 在 r 中读取 csv (1)
- pandas read_csv 随机行 - Python (1)
- pandas 读取到 csv 文件 - Python (1)
- 在 pandas 中读取 csv 文件 - Python (1)
- pandas 读取 csv 文件 - Python (1)
- pandas read_csv 随机行 - Python 代码示例
- 读取csv python代码示例
- pandas 读取 csv 文件 - Python 代码示例
- 在 pandas 中读取 csv 文件 - Python 代码示例
- pandas 读取到 csv 文件 - Python 代码示例
- csv 到 python (1)
- python中的csv(1)
- python 从 csv 读取列 - Python (1)
- python 读取 csv - Python (1)
- csv (1)
- 使用 csv 模块如何读取 csv 中的特定行 - Python (1)
- pandas 从 url 读取 csv - Python (1)
- pandas read_csv 列名 - Python (1)
📅 最后修改于: 2020-04-21 13:20:02 🧑 作者: Mango
Python是进行数据分析的一种出色语言,主要是因为以数据为中心的Python软件包具有奇妙的生态系统。Pandas是其中的一种,使导入和分析数据更加容易。
导入 Pandas:
import pandas as pd代码#1:read_csv是重要的pandas函数,用于读取csv文件并对其进行操作。
# 导入 pandas
import pandas as pd
# 读取csv文件
pd.read_csv("filename.csv")通过此操作轻松打开CSV文件。但是还有很多其他事情可以通过此函数来完成,以完全更改返回的对象。例如,不仅可以在本地读取csv文件,还可以通过read_csv从URL读取csv文件,也可以选择需要导出的列,这样我们以后就不必编辑数组了。
这是其默认值所采用的参数列表。
pd.read_csv(filepath_or_buffer, sep=’, ‘, delimiter=None, header=’infer’, names=None, index_col=None, usecols=None, squeeze=False, prefix=None, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=False, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, iterator=False, chunksize=None, compression=’infer’, thousands=None, decimal=b’.’, lineterminator=None, quotechar='”‘, quoting=0, escapechar=None, comment=None, encoding=None, dialect=None, tupleize_cols=None, error_bad_lines=True, warn_bad_lines=True, skipfooter=0, doublequote=True, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None)
并非所有参数都非常重要,但记住这些函数实际上可以节省自己执行相同函数的时间。通过按Jupyter Notebook中的Shift + Tab,可以看到任何函数的参数。下面列出了有用的用法:
| 参数 | 采用 |
|---|---|
| filepath_or_buffer | 文件的URL或目录位置 |
| sep | 代表分隔符,默认为’,’,如csv(逗号分隔值) |
| index_col | 将传递的列设为索引,而不是0、1、2、3…r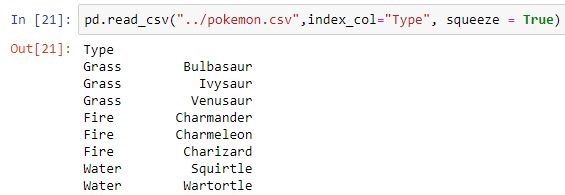  |
| header | 将传递的行/ s [int / int列表]作为标题 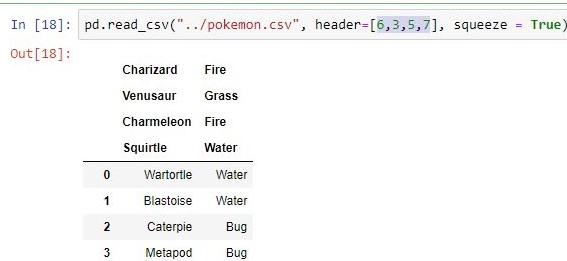 |
| use_cols | 仅使用传递的col [string list]制作数据帧 |
| squeeze | 如果为true,并且仅传递一列,则返回pandas系列 |
| skiprows | 跳过新数据框中传递的行 |
代码2:
# 导入pandas
import pandas as pd
pd.read_csv(filepath_or_buffer = "pokemon.csv")
# makes the passed rows header
pd.read_csv("pokemon.csv", header =[1, 2])
# 使传递的列作为索引而不是0、1、2、3 ...
pd.read_csv("pokemon.csv", index_col ='Type')
pd.read_csv("pokemon.csv", usecols =["Type"])
# reutruns pandas系列,如果只有一个列
pd.read_csv("pokemon.csv", usecols =["Type"],
squeeze = True)
# 跳过新series中传递的行
pd.read_csv("pokemon.csv",
skiprows = [1, 2, 3, 4])