使用简单的 HTML DOM 解析器在PHP抓取网页
Web Scraping 是一种用于从网站中提取大量数据的技术,这些数据被提取并保存到计算机中的本地文件或数据库中,或者可以用作 API。大多数网站显示的数据只能使用网络浏览器查看。它们不提供保存此数据副本以供使用的功能。因此,唯一的选择是复制和粘贴所需的选定数据,这实际上是一项非常乏味的工作,可能需要数小时才能完成。换句话说,Web Scraping 是一种自动化此类过程的技术,代替手动工作,Web Scraping 软件可在几秒钟内执行相同的任务。网页抓取可以通过将选定的 DOM 组件作为目标,然后处理或存储网页的该 DOM 元素之间的文本来完成。为了在PHP做同样的事情,有一个 API 可以解析整个页面并在 DOM 中查找所需的元素。它是简单的 HTML DOM 解析器。要了解有关 Web Scraping 的更多信息,请访问本文。
可以通过单击此链接下载它。
示例 1:下面给出的示例显示了使用此 API 来显示本地主机上的 google 搜索。
- HTML代码:
Document - PHP代码:
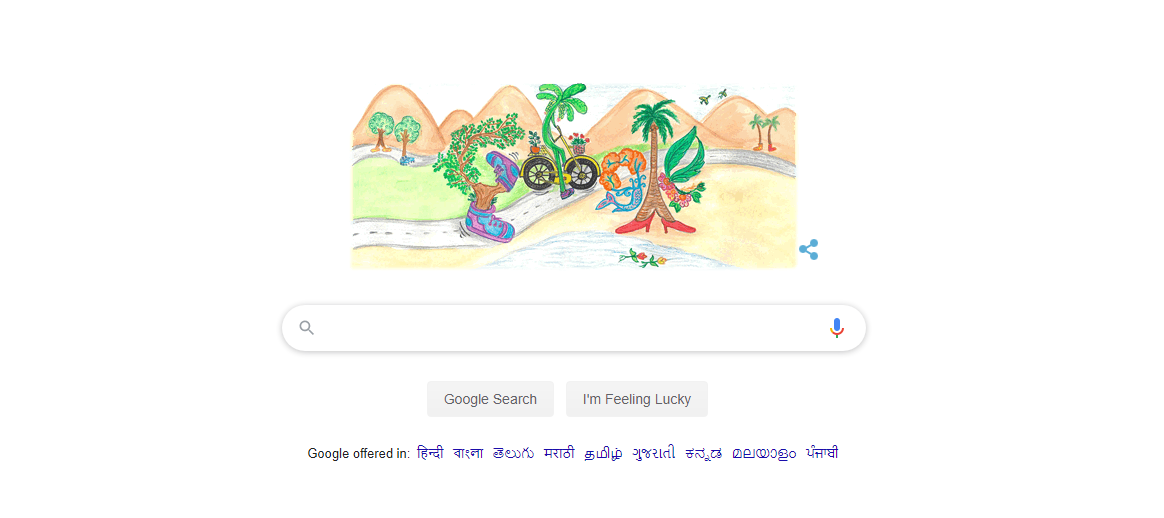
输出:本地服务器上的输出是
示例 2:这里我们将尝试访问 google 的第一个搜索结果上的文本。为此,我们首先将具有第一个结果的 DOM 组件获取到向 google 询问的查询中。在这里,我们从 DOM 中获取具有类“kCrYT”的 span 标签,其中包含所有搜索的详细信息列表,但我们只需要第一个,因此循环只迭代一次。
- PHP代码:如果您已经在 Google 搜索引擎上搜索过任何内容,则此代码将起作用。
find('div.kCrYT') as $elements) { echo $elements->plaintext; break; } ?> - 输出:
GeeksforGeeks is a very fast-growing community among programmers and have a reach of around 10 million+ readers globally. Writing will surely enhance your knowledge of the subject as before writing any topic, you need to be very crisp and clear about it.
- PHP代码:如果您已经在 Google 搜索引擎上搜索过任何内容,则此代码将起作用。