在Python中使用 Web Scraping 进行报价猜谜游戏
先决条件: BeautifulSoup 安装
在本文中,我们将使用名为 BeautifulSoup 的Python框架从该站点 http//quotes.toscrape.com 中抓取作者的报价和详细信息,并使用不同的数据结构和算法开发一个猜谜游戏。
用户将有 4 次机会猜出名言的作者,每一次都会向用户提供提示,可以是作者的出生日期、名字的第一个字母、第二个名字的第一个字母等。 成功猜出对于作者,会打印一条消息,如果用户在所有 4 次机会之后都未能猜到答案,则会再次打印一条消息以及答案。
方法
- 导入模块
- requests 帮助我们抓取页面,当收到响应时,它以字符串的形式存储
- bs4 库用于创建 beasutifulSoup 对象。
- csv库帮助使用Python读取和写入 CSV 文件
- 时间模块的睡眠函数有助于增加程序执行的延迟。
- 来自 random 模块的选择函数返回一个随机元素。
- 创建一个列表来存储刮取的值
- 从此链接中抓取详细信息: http//quotes.toscrape.com
- 提取数据
- 游戏逻辑
- 从创建的字典中返回随机项目
- 设置猜测次数
- 写成功和失败的消息
- 不断给出提示,直到机会数达到零或用户做对了
程序:
Python3
import requests
from bs4 import BeautifulSoup
from csv import writer
from time import sleep
from random import choice
# list to store scraped data
all_quotes = []
# this part of the url is constant
base_url = "http://quotes.toscrape.com/"
# this part of the url will keep changing
url = "/page/1"
while url:
# concatenating both urls
# making request
res = requests.get(f"{base_url}{url}")
print(f"Now Scraping{base_url}{url}")
soup = BeautifulSoup(res.text, "html.parser")
# extracting all elements
quotes = soup.find_all(class_="quote")
for quote in quotes:
all_quotes.append({
"text": quote.find(class_="text").get_text(),
"author": quote.find(class_="author").get_text(),
"bio-link": quote.find("a")["href"]
})
next_btn = soup.find(_class="next")
url = next_btn.find("a")["href"] if next_btn else None
sleep(2)
quote = choice(all_quotes)
remaining_guesses = 4
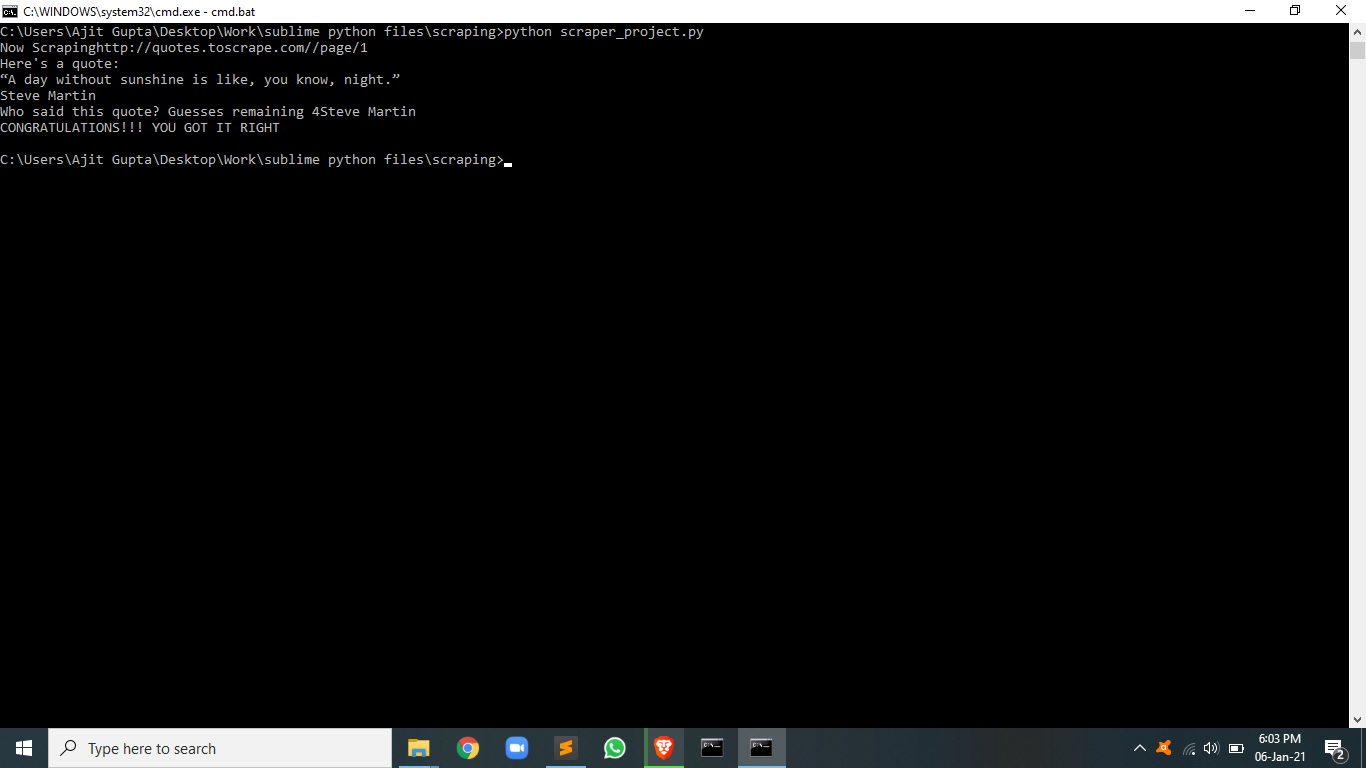
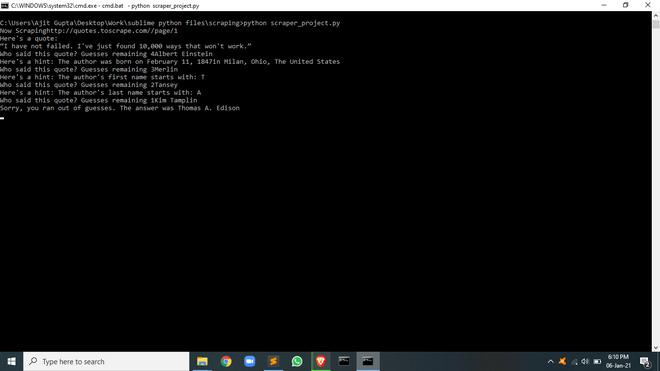
print("Here's a quote: ")
print(quote["text"])
guess = ''
while guess.lower() != quote["author"].lower() and remaining_guesses > 0:
guess = input(
f"Who said this quote? Guesses remaining {remaining_guesses}")
if guess == quote["author"]:
print("CONGRATULATIONS!!! YOU GOT IT RIGHT")
break
remaining_guesses -= 1
if remaining_guesses == 3:
res = requests.get(f"{base_url}{quote['bio-link']}")
soup = BeautifulSoup(res.text, "html.parser")
birth_date = soup.find(class_="author-born-date").get_text()
birth_place = soup.find(class_="author-born-location").get_text()
print(
f"Here's a hint: The author was born on {birth_date}{birth_place}")
elif remaining_guesses == 2:
print(
f"Here's a hint: The author's first name starts with: {quote['author'][0]}")
elif remaining_guesses == 1:
last_initial = quote["author"].split(" ")[1][0]
print(
f"Here's a hint: The author's last name starts with: {last_initial}")
else:
print(
f"Sorry, you ran out of guesses. The answer was {quote['author']}")输出: