Python中的数据整理
数据整理是收集、收集原始数据并将其转换为另一种格式的过程,以便在更短的时间内更好地理解、决策、访问和分析。数据整理也称为数据处理。

数据整理的重要性
数据整理是非常重要的一步。下面的例子将解释它的重要性:
图书销售网站希望根据用户偏好展示不同领域的畅销图书。例如,一个新用户搜索励志书籍,然后他们想展示那些销量最高或评分高的励志书籍等。
但是在他们的网站上,有大量来自不同用户的原始数据。这里使用了数据处理或数据整理的概念。正如我们所知,数据不是由系统整理的。这个过程是由数据科学家完成的。所以,数据科学家会以这样一种方式来整理数据,他们会对销量更高或评分高的励志书籍进行排序,或者用户用这些书籍包购买这本书等。在此基础上,新用户将做出选择。这将解释数据整理的重要性。
Python中的数据整理
数据整理是数据科学和数据分析的关键主题。 Python的 Pandas 框架用于数据整理。 Pandas 是一个专门为数据分析和数据科学开发的开源库。数据排序或过滤、数据分组等过程。
Python中的数据处理处理以下功能:
- 数据探索:在此过程中,通过可视化数据表示来研究、分析和理解数据。
- 处理缺失值:大部分数据量很大的数据集都包含NaN的缺失值,需要小心处理 通过将它们替换为均值、众数、列的最频繁值或简单地删除具有NaN值的行。
- 重塑数据:在此过程中,根据需求对数据进行操作,可以添加新数据或修改预先存在的数据。
- 过滤数据:有时数据集由不需要的行或列组成,需要删除或过滤
- 其他:在处理完具有上述功能的原始数据集后,我们会根据我们的要求获得一个高效的数据集,然后可以将其用于所需的目的,如数据分析、机器学习、数据可视化、模型训练等。
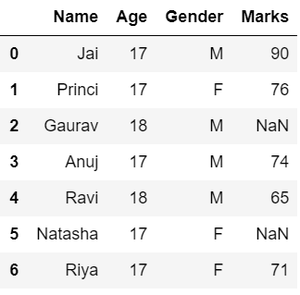
以下是在原始数据集上实现上述功能的示例:
- 数据探索,这里我们分配数据,然后我们以表格格式将数据可视化。
Python3
# Import pandas package
import pandas as pd
# Assign data
data = {'Name': ['Jai', 'Princi', 'Gaurav',
'Anuj', 'Ravi', 'Natasha', 'Riya'],
'Age': [17, 17, 18, 17, 18, 17, 17],
'Gender': ['M', 'F', 'M', 'M', 'M', 'F', 'F'],
'Marks': [90, 76, 'NaN', 74, 65, 'NaN', 71]}
# Convert into DataFrame
df = pd.DataFrame(data)
# Display data
dfPython3
# Compute average
c = avg = 0
for ele in df['Marks']:
if str(ele).isnumeric():
c += 1
avg += ele
avg /= c
# Replace missing values
df = df.replace(to_replace="NaN",
value=avg)
# Display data
dfPython3
# Categorize gender
df['Gender'] = df['Gender'].map({'M': 0,
'F': 1, }).astype(float)
# Display data
dfPython3
# Filter top scoring students
df = df[df['Marks'] >= 75]
# Remove age row
df = df.drop(['Age'], axis=1)
# Display data
dfPython3
# import module
import pandas as pd
# creating DataFrame for Student Details
details = pd.DataFrame({
'ID': [101, 102, 103, 104, 105, 106,
107, 108, 109, 110],
'NAME': ['Jagroop', 'Praveen', 'Harjot',
'Pooja', 'Rahul', 'Nikita',
'Saurabh', 'Ayush', 'Dolly', "Mohit"],
'BRANCH': ['CSE', 'CSE', 'CSE', 'CSE', 'CSE',
'CSE', 'CSE', 'CSE', 'CSE', 'CSE']})
# printing details
print(details)Python3
# Import module
import pandas as pd
# Creating Dataframe for Fees_Status
fees_status = pd.DataFrame(
{'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'PENDING': ['5000', '250', 'NIL',
'9000', '15000', 'NIL',
'4500', '1800', '250', 'NIL']})
# Printing fees_status
print(fees_status)Python3
# Import module
import pandas as pd
# Creating Dataframe
details = pd.DataFrame({
'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'NAME': ['Jagroop', 'Praveen', 'Harjot',
'Pooja', 'Rahul', 'Nikita',
'Saurabh', 'Ayush', 'Dolly', "Mohit"],
'BRANCH': ['CSE', 'CSE', 'CSE', 'CSE', 'CSE',
'CSE', 'CSE', 'CSE', 'CSE', 'CSE']})
# Creating Dataframe
fees_status = pd.DataFrame(
{'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'PENDING': ['5000', '250', 'NIL',
'9000', '15000', 'NIL',
'4500', '1800', '250', 'NIL']})
# Merging Dataframe
print(pd.merge(details, fees_status, on='ID'))Python3
# Import module
import pandas as pd
# Creating Data
car_selling_data = {'Brand': ['Maruti', 'Maruti', 'Maruti',
'Maruti', 'Hyundai', 'Hyundai',
'Toyota', 'Mahindra', 'Mahindra',
'Ford', 'Toyota', 'Ford'],
'Year': [2010, 2011, 2009, 2013,
2010, 2011, 2011, 2010,
2013, 2010, 2010, 2011],
'Sold': [6, 7, 9, 8, 3, 5,
2, 8, 7, 2, 4, 2]}
# Creating Dataframe of car_selling_data
df = pd.DataFrame(car_selling_data)
# printing Dataframe
print(df)Python3
# Import module
import pandas as pd
# Creating Data
car_selling_data = {'Brand': ['Maruti', 'Maruti', 'Maruti',
'Maruti', 'Hyundai', 'Hyundai',
'Toyota', 'Mahindra', 'Mahindra',
'Ford', 'Toyota', 'Ford'],
'Year': [2010, 2011, 2009, 2013,
2010, 2011, 2011, 2010,
2013, 2010, 2010, 2011],
'Sold': [6, 7, 9, 8, 3, 5,
2, 8, 7, 2, 4, 2]}
# Creating Dataframe for Provided Data
df = pd.DataFrame(car_selling_data)
# Group the data when year = 2010
grouped = df.groupby('Year')
print(grouped.get_group(2010))Python3
# Import module
import pandas as pd
# Initializing Data
student_data = {'Name': ['Amit', 'Praveen', 'Jagroop',
'Rahul', 'Vishal', 'Suraj',
'Rishab', 'Satyapal', 'Amit',
'Rahul', 'Praveen', 'Amit'],
'Roll_no': [23, 54, 29, 36, 59, 38,
12, 45, 34, 36, 54, 23],
'Email': ['xxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxx@gmail.com', 'xx@gmail.com',
'xxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxxxxxx@gmail.com', 'xxxxxxxxxx@gmail.com']}
# Creating Dataframe of Data
df = pd.DataFrame(student_data)
# Printing Dataframe
print(df)Python3
# import module
import pandas as pd
# initializing Data
student_data = {'Name': ['Amit', 'Praveen', 'Jagroop',
'Rahul', 'Vishal', 'Suraj',
'Rishab', 'Satyapal', 'Amit',
'Rahul', 'Praveen', 'Amit'],
'Roll_no': [23, 54, 29, 36, 59, 38,
12, 45, 34, 36, 54, 23],
'Email': ['xxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxx@gmail.com', 'xx@gmail.com',
'xxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxxxxxx@gmail.com', 'xxxxxxxxxx@gmail.com']}
# creating dataframe
df = pd.DataFrame(student_data)
# Here df.duplicated() list duplicate Entries in ROllno.
# So that ~(NOT) is placed in order to get non duplicate values.
non_duplicate = df[~df.duplicated('Roll_no')]
# printing non-duplicate values
print(non_duplicate)输出:
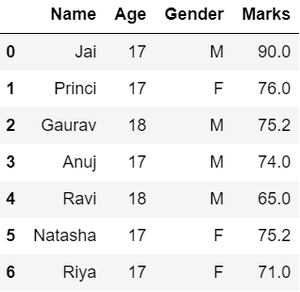
- 处理缺失值,正如我们从前面的输出中看到的那样, MARKS列中存在NaN值,将通过将它们替换为列均值来处理这些值。
蟒蛇3
# Compute average
c = avg = 0
for ele in df['Marks']:
if str(ele).isnumeric():
c += 1
avg += ele
avg /= c
# Replace missing values
df = df.replace(to_replace="NaN",
value=avg)
# Display data
df
输出:
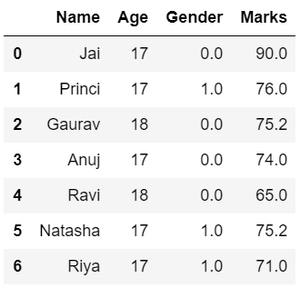
- 重塑数据,在GENDER列中,我们可以通过将数据分类为不同的数字来重塑数据。
蟒蛇3
# Categorize gender
df['Gender'] = df['Gender'].map({'M': 0,
'F': 1, }).astype(float)
# Display data
df
输出:
- 过滤数据,假设有要求提供高分学生的姓名、性别、分数等详细信息。这里我们需要删除一些不需要的数据。
蟒蛇3
# Filter top scoring students
df = df[df['Marks'] >= 75]
# Remove age row
df = df.drop(['Age'], axis=1)
# Display data
df
输出:
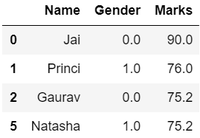
因此,我们最终获得了一个有效的数据集,可以进一步用于各种目的。
现在我们知道了数据整理的基础知识。下面我们将讨论可以执行数据整理的各种操作:
使用合并操作整理数据
合并操作用于将原始数据合并成所需的格式。
句法:
pd.merge( data_frame1,data_frame2, on="field ") 这里的字段是在两个数据框上都相似的列的名称。
例如:假设教师有两种类型的数据,第一种类型的数据包括学生的详细信息,第二种类型的数据包括从会计处获取的待处理费用状态。所以老师会在这里使用合并操作来合并数据并赋予其意义。这样老师就可以轻松地分析它,也可以减少手动合并老师的时间和精力。
第一类数据:
蟒蛇3
# import module
import pandas as pd
# creating DataFrame for Student Details
details = pd.DataFrame({
'ID': [101, 102, 103, 104, 105, 106,
107, 108, 109, 110],
'NAME': ['Jagroop', 'Praveen', 'Harjot',
'Pooja', 'Rahul', 'Nikita',
'Saurabh', 'Ayush', 'Dolly', "Mohit"],
'BRANCH': ['CSE', 'CSE', 'CSE', 'CSE', 'CSE',
'CSE', 'CSE', 'CSE', 'CSE', 'CSE']})
# printing details
print(details)
输出:

第二种数据
蟒蛇3
# Import module
import pandas as pd
# Creating Dataframe for Fees_Status
fees_status = pd.DataFrame(
{'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'PENDING': ['5000', '250', 'NIL',
'9000', '15000', 'NIL',
'4500', '1800', '250', 'NIL']})
# Printing fees_status
print(fees_status)
输出:
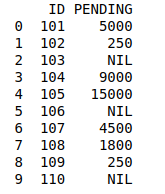
使用合并操作整理数据:
蟒蛇3
# Import module
import pandas as pd
# Creating Dataframe
details = pd.DataFrame({
'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'NAME': ['Jagroop', 'Praveen', 'Harjot',
'Pooja', 'Rahul', 'Nikita',
'Saurabh', 'Ayush', 'Dolly', "Mohit"],
'BRANCH': ['CSE', 'CSE', 'CSE', 'CSE', 'CSE',
'CSE', 'CSE', 'CSE', 'CSE', 'CSE']})
# Creating Dataframe
fees_status = pd.DataFrame(
{'ID': [101, 102, 103, 104, 105,
106, 107, 108, 109, 110],
'PENDING': ['5000', '250', 'NIL',
'9000', '15000', 'NIL',
'4500', '1800', '250', 'NIL']})
# Merging Dataframe
print(pd.merge(details, fees_status, on='ID'))
输出:

使用分组方法整理数据
数据分析中的分组方法用于根据从大数据中提取的各种组来提供结果。 Pandas 的这种方法用于从大数据集中对数据的开始进行分组。
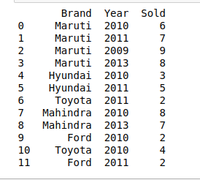
示例:有一家汽车销售公司,该公司拥有各种汽车制造公司的不同品牌,例如 Maruti、Toyota、Mahindra、Ford 等,并且有不同年份销售不同汽车的数据。因此,该公司只想处理 2010 年销售汽车的数据。对于这个问题,我们使用另一种 Wrangling 技术,即groupby()方法。
汽车销售数据:
蟒蛇3
# Import module
import pandas as pd
# Creating Data
car_selling_data = {'Brand': ['Maruti', 'Maruti', 'Maruti',
'Maruti', 'Hyundai', 'Hyundai',
'Toyota', 'Mahindra', 'Mahindra',
'Ford', 'Toyota', 'Ford'],
'Year': [2010, 2011, 2009, 2013,
2010, 2011, 2011, 2010,
2013, 2010, 2010, 2011],
'Sold': [6, 7, 9, 8, 3, 5,
2, 8, 7, 2, 4, 2]}
# Creating Dataframe of car_selling_data
df = pd.DataFrame(car_selling_data)
# printing Dataframe
print(df)
输出:
2010 年度数据:
蟒蛇3
# Import module
import pandas as pd
# Creating Data
car_selling_data = {'Brand': ['Maruti', 'Maruti', 'Maruti',
'Maruti', 'Hyundai', 'Hyundai',
'Toyota', 'Mahindra', 'Mahindra',
'Ford', 'Toyota', 'Ford'],
'Year': [2010, 2011, 2009, 2013,
2010, 2011, 2011, 2010,
2013, 2010, 2010, 2011],
'Sold': [6, 7, 9, 8, 3, 5,
2, 8, 7, 2, 4, 2]}
# Creating Dataframe for Provided Data
df = pd.DataFrame(car_selling_data)
# Group the data when year = 2010
grouped = df.groupby('Year')
print(grouped.get_group(2010))
输出:
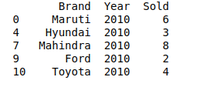
通过删除重复来整理数据
Pandas duplicates()方法帮助我们从大数据中删除重复值。数据整理的一个重要部分是从大数据集中删除重复值。
句法:
DataFrame.duplicated(subset=None, keep='first')这里子集是我们要删除重复值的列值。
为了保持,我们有 3 个选择:
- 如果keep ='first'然后第一个值被标记为原始其余所有值如果发生将被删除,因为它被认为是重复的。
- 如果keep='last'那么最后一个值被标记为原始其余所有高于相同值的将被删除,因为它被视为重复值。
- 如果keep ='false' ,则所有出现多次的值都将被删除,因为所有值都被视为重复值。
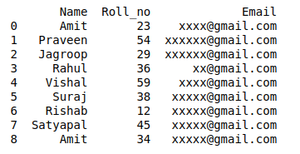
例如,A 大学将组织该活动。为了参与,学生必须在在线表格中填写他们的详细信息,以便他们与他们联系。学生可能会多次填写表格。如果一个学生填写多个条目,可能会给活动组织者带来困难。组织者将获得的数据可以通过删除重复值轻松解决。
想要参加活动的详细学生资料:
蟒蛇3
# Import module
import pandas as pd
# Initializing Data
student_data = {'Name': ['Amit', 'Praveen', 'Jagroop',
'Rahul', 'Vishal', 'Suraj',
'Rishab', 'Satyapal', 'Amit',
'Rahul', 'Praveen', 'Amit'],
'Roll_no': [23, 54, 29, 36, 59, 38,
12, 45, 34, 36, 54, 23],
'Email': ['xxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxx@gmail.com', 'xx@gmail.com',
'xxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxxxxxx@gmail.com', 'xxxxxxxxxx@gmail.com']}
# Creating Dataframe of Data
df = pd.DataFrame(student_data)
# Printing Dataframe
print(df)
输出:
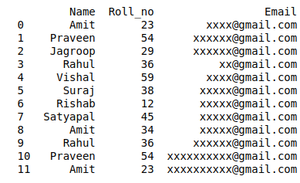
由于删除重复条目而造成的数据混乱:
蟒蛇3
# import module
import pandas as pd
# initializing Data
student_data = {'Name': ['Amit', 'Praveen', 'Jagroop',
'Rahul', 'Vishal', 'Suraj',
'Rishab', 'Satyapal', 'Amit',
'Rahul', 'Praveen', 'Amit'],
'Roll_no': [23, 54, 29, 36, 59, 38,
12, 45, 34, 36, 54, 23],
'Email': ['xxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxx@gmail.com', 'xx@gmail.com',
'xxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxx@gmail.com',
'xxxxx@gmail.com', 'xxxxxx@gmail.com',
'xxxxxxxxxx@gmail.com', 'xxxxxxxxxx@gmail.com']}
# creating dataframe
df = pd.DataFrame(student_data)
# Here df.duplicated() list duplicate Entries in ROllno.
# So that ~(NOT) is placed in order to get non duplicate values.
non_duplicate = df[~df.duplicated('Roll_no')]
# printing non-duplicate values
print(non_duplicate)
输出: