- zookeeper 2 (1)
- 工作流程流程(1)
- 工作流程流程
- zookeeper 2 - 任何代码示例
- Zookeeper-安装
- Zookeeper-安装(1)
- Zookeeper-API(1)
- Zookeeper-API
- Zookeeper-应用程序(1)
- Zookeeper-应用程序
- Zookeeper教程(1)
- Zookeeper教程
- 讨论Zookeeper
- Zookeeper-概述
- Zookeeper-概述(1)
- Zookeeper-CLI
- 在工作流程中使用变量 (1)
- Node.js的工作流程(1)
- Node.js的工作流程
- 将脚本添加到您的工作流程 (1)
- Zookeeper-基础知识(1)
- Zookeeper-基础知识
- Zookeeper-有用的资源(1)
- Zookeeper-有用的资源
- Ansible工作流程
- Ansible工作流程(1)
- AWK-工作流程
- AWK-工作流程(1)
- redux 工作流程 - Javascript (1)
📅 最后修改于: 2020-11-28 14:25:00 🧑 作者: Mango
ZooKeeper合奏启动后,它将等待客户端连接。客户端将连接到ZooKeeper集成中的节点之一。它可以是领导者节点或跟随者节点。客户端连接后,节点将为特定客户端分配会话ID,并向该客户端发送确认。如果客户端未收到确认,则仅尝试连接ZooKeeper集成中的另一个节点。一旦连接到节点,客户端将定期发送心跳信号到该节点,以确保连接不会丢失。
-
如果客户端要读取特定的znode,则它将具有znode路径的读取请求发送到该节点,并且该节点通过从其自己的数据库获取请求的znode来返回该请求。因此,在ZooKeeper合奏中读取速度很快。
-
如果客户端希望将数据存储在ZooKeeper集合中,则它将znode路径和数据发送到服务器。连接的服务器会将请求转发给领导者,然后领导者将向所有关注者重新发出书写请求。如果只有大多数节点成功响应,则写请求将成功,并且成功的返回码将发送到客户端。否则,写入请求将失败。严格的大多数节点称为Quorum 。
ZooKeeper合奏中的节点
让我们分析一下ZooKeeper集合中具有不同数量节点的影响。
-
如果我们只有一个节点,则当该节点发生故障时,ZooKeeper集成也会失败。它会导致“单点故障”,因此在生产环境中不建议使用。
-
如果我们有两个节点,并且一个节点发生故障,那么我们也不会拥有多数,因为两个之中的一个不是多数。
-
如果我们有三个节点,而一个节点出现故障,则我们占多数,因此这是最低要求。 ZooKeeper集成必须在实时生产环境中至少具有三个节点。
-
如果我们有四个节点,而两个节点发生故障,那么它将再次失败,这类似于具有三个节点。多余的节点没有任何作用,因此,最好以奇数(例如3、5、7)添加节点。
我们知道,在ZooKeeper集成中,写入过程比读取过程昂贵,因为所有节点都需要在其数据库中写入相同的数据。因此,对于平衡的环境,拥有较少数量的节点(3、5或7)比拥有大量节点更好。
下图描述了ZooKeeper WorkFlow,随后的表格说明了其不同的组件。
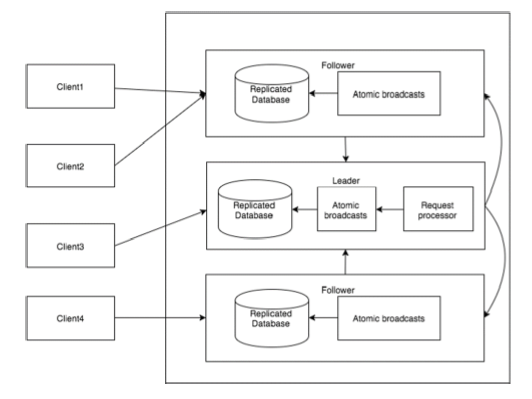
| Component | Description |
|---|---|
| Write | Write process is handled by the leader node. The leader forwards the write request to all the znodes and waits for answers from the znodes. If half of the znodes reply, then the write process is complete. |
| Read | Reads are performed internally by a specific connected znode, so there is no need to interact with the cluster. |
| Replicated Database | It is used to store data in zookeeper. Each znode has its own database and every znode has the same data at every time with the help of consistency. |
| Leader | Leader is the Znode that is responsible for processing write requests. |
| Follower | Followers receive write requests from the clients and forward them to the leader znode. |
| Request Processor | Present only in leader node. It governs write requests from the follower node. |
| Atomic broadcasts | Responsible for broadcasting the changes from the leader node to the follower nodes. |