- scikit learn - Python (1)
- scikit learn - Python 代码示例
- Scikit学习-使用PCA减少维度
- Scikit学习-使用PCA减少维度(1)
- scikit learn 的版本 - Python (1)
- scikit learn 的版本 - Python 代码示例
- scikit learn 介绍 - Python (1)
- scikit-learn 教程 (1)
- 如何安装 scikit learn python 库 - Shell-Bash (1)
- scikit learn 介绍 - Python 代码示例
- 管道Python和 scikit-learn(1)
- 管道Python和 scikit-learn
- 安装 scikit learn - Shell-Bash (1)
- scikit learn 介绍 (1)
- 如何安装 scikit learn python 库 - Shell-Bash 代码示例
- 安装 scikit learn - Shell-Bash 代码示例
- 如何在 Linux 上安装 Scikit-Learn?
- 如何在 Linux 上安装 Scikit-Learn?(1)
- 使用 scikit-learn 进行多类分类
- 使用 scikit-learn 进行多类分类(1)
- scikit learn k mean - Python (1)
- scikit-learn 教程 - 任何代码示例
- 如何在 Windows 中安装 Scikit-Learn?
- 如何在 Windows 中安装 Scikit-Learn?(1)
- scikit learn k mean - Python 代码示例
- 在 scikit learn 中编码标签 - Python 代码示例
- scikit learn 介绍 - 任何代码示例
- 使用 scikit-learn 库的多项式回归 - Python (1)
- scikit-learn 安装错误 - Shell-Bash (1)
📅 最后修改于: 2020-09-02 05:17:56 🧑 作者: Mango
介绍
在机器学习中,模型的性能仅受益于直到特定点的更多功能。将更多的特征输入到模型中,数据的维数增加的越多。随着尺寸的增加,过度装配的可能性更高。
可以使用多种技术来解决过度拟合问题,但是降维是最有效的技术之一。降维选择要素空间中最重要的组成部分,保留它们并删除其他组成部分。
为什么需要降维?
在机器学习中使用降维有以下几个原因:对抗计算成本,控制过度拟合以及可视化和帮助解释高维数据集。
通常在机器学习中,数据集中显示的功能越多,分类器就可以学习越好。但是,更多的功能也意味着更高的计算成本。高维不仅会导致训练时间长,而且更多特征通常会导致算法过度拟合,因为它试图创建一个解释数据中所有特征的模型。
因为降维减少了特征的总数,所以它可以减少与训练模型相关的计算需求,而且还可以通过保持将要馈入模型的特征相当简单来帮助防止过度拟合。
降维可以在有监督和无监督的学习环境中使用。在无监督学习的情况下,降维通常用于通过执行特征选择或特征提取来预处理数据。
用于进行无监督学习的降维的主要算法是主成分分析(PCA)和奇异值分解(SVD)。
在监督学习的情况下,降维可用于简化输入到机器学习分类器中的功能。用于进行有监督的学习问题的降维的最常用方法是线性判别分析(LDA)和PCA,并且可以用来预测新情况。
请注意,上述用例是一般用例,并非使用这些技术的唯一条件。毕竟,降维技术是统计方法,其使用不受机器学习模型的限制。
让我们花一些时间来解释每种最常见的降维技术背后的想法。
主成分分析
主成分分析(PCA)是一种统计方法,可以通过分析数据集的特征来创建数据的新特征或特征。本质上,数据的特征被汇总或组合在一起。您还可以将主成分分析视为将数据从更高维度的空间“压缩”到几个维度。
更具体地讲,一种饮料可能由许多功能来描述,但是这些功能中的许多功能对于识别所讨论的饮料都是多余的,相对来说是无用的。与其用通气,CO2水平等特征描述葡萄酒,不如用颜色,味道和年龄来描述它们。
主成分分析选择数据集的“主要”或最具影响力的特征,并基于这些特征创建特征。通过仅选择对数据集影响最大的特征,可减少维数。
PCA在创建新功能时会保留变量之间的相关性。该技术创建的主要成分是原始变量的线性组合,并使用称为特征向量的概念进行了计算。
假定新组件是正交的,或彼此不相关。
PCA实施示例
让我们看一下如何在Scikit-Learn中实现PCA 。我们将为此使用蘑菇分类数据集。
import pandas as pd
import matplotlib.pyplot as plt
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.decomposition import PCA
from sklearn.model_selection import train_test_split
import warnings
warnings.filterwarnings("ignore")
首先,我们需要导入所需的所有模块,其中包括PCA,train_test_split标签和缩放工具:
m_data = pd.read_csv('mushrooms.csv')
# Machine learning systems work with integers, we need to encode these
# string characters into ints
encoder = LabelEncoder()
# Now apply the transformation to all the columns:
for col in m_data.columns:
m_data[col] = encoder.fit_transform(m_data[col])
X_features = m_data.iloc[:,1:23]
y_label = m_data.iloc[:, 0]
现在,我们将使用标准缩放器缩放功能。这是可选的,因为我们实际上没有运行分类器,但是它可能会影响PCA分析数据的方式:
# Scale the features
scaler = StandardScaler()
X_features = scaler.fit_transform(X_features)现在,我们将使用PCA来获取要素列表,并绘制出具有最大解释力或差异最大的要素。这些是主要组成部分。大约有17或18个功能可以解释大多数数据,几乎占我们数据的95%:
# Visualize
pca = PCA()
pca.fit_transform(X_features)
pca_variance = pca.explained_variance_
plt.figure(figsize=(8, 6))
plt.bar(range(22), pca_variance, alpha=0.5, align='center', label='individual variance')
plt.legend()
plt.ylabel('Variance ratio')
plt.xlabel('Principal components')
plt.show()让我们将功能转换为17个主要功能。然后,我们将基于以下17个功能绘制数据点分类的散点图:
pca2 = PCA(n_components=17)
pca2.fit(X_features)
x_3d = pca2.transform(X_features)
plt.figure(figsize=(8,6))
plt.scatter(x_3d[:,0], x_3d[:,5], c=m_data['class'])
plt.show() 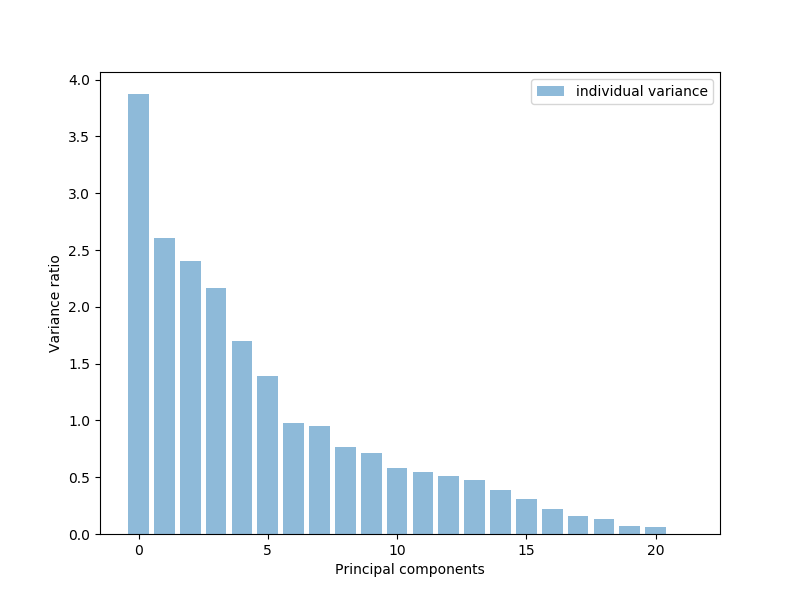
让我们将功能转换为17个主要功能。然后,我们将基于以下17个功能绘制数据点分类的散点图:
pca2 = PCA(n_components=17)
pca2.fit(X_features)
x_3d = pca2.transform(X_features)
plt.figure(figsize=(8,6))
plt.scatter(x_3d[:,0], x_3d[:,5], c=m_data['class'])
plt.show()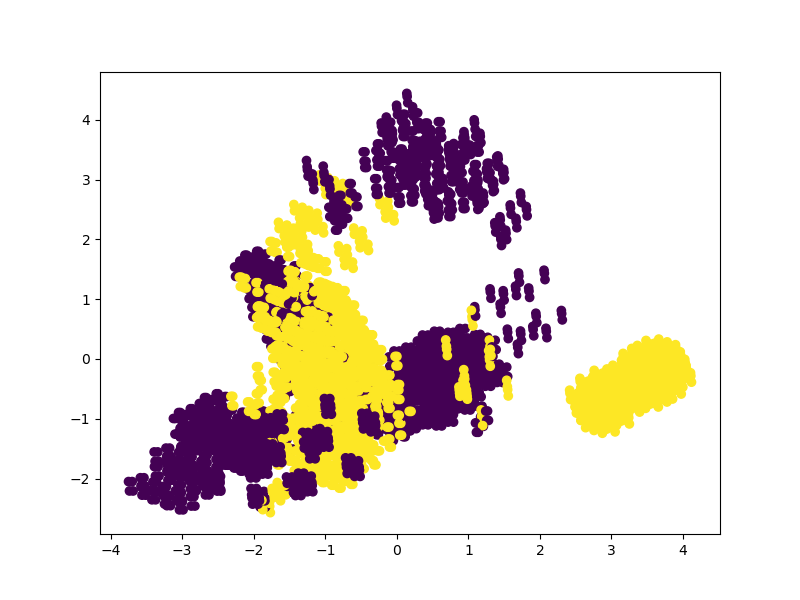
我们还对前2个功能进行此操作,并查看分类如何变化:
pca3 = PCA(n_components=2)
pca3.fit(X_features)
x_3d = pca3.transform(X_features)
plt.figure(figsize=(8,6))
plt.scatter(x_3d[:,0], x_3d[:,1], c=m_data['class'])
plt.show()
奇异值分解
奇异值分解的目的是简化矩阵并简化使用矩阵的计算。类似于PCA的目标,矩阵被简化为其组成部分。在机器学习模型中实现SVD的来龙去脉并不是完全必要的,但是对SVD的工作方式有一个直观的了解将使您更好地了解何时使用它。
SVD可以在复杂矩阵或实值矩阵上执行,但是为了使这种解释更容易理解,我们将介绍分解实值矩阵的方法。
在执行SVD时,我们要在矩阵中填充数据,并希望减少矩阵的列数。这降低了矩阵的维数,同时仍保留了数据中尽可能多的可变性。
我们可以说矩阵A等于矩阵V的转置:
![]()
假设我们有一些矩阵A中,我们可以表示矩阵三个称为其它基质ü,V,和d。矩阵A具有原始的x * y元素,而矩阵U是包含x * x元素的正交矩阵,矩阵V是包含y * y元素的不同正交矩阵。最后,D是一个包含x * y元素的对角矩阵。
分解矩阵的值涉及将原始矩阵中的奇异值转换为新矩阵的对角线值。如果将正交矩阵乘以其他数字,则它们的属性不会改变,我们可以利用此属性获得矩阵A的近似值。当乘以正交矩阵时矩阵的转置组合在一起V,我们得到了一个矩阵,它等效于原始矩阵甲。
当我们将矩阵A分解/分解为U,D和V时,我们将得到三个包含矩阵A信息的不同矩阵。
事实证明,矩阵的最左边的列保存我们的大多数数据,我们可以只选择这几个列有矩阵的一个很好的近似一个。这种新矩阵的尺寸要少得多,因此更容易使用。
SVD实现示例
使用SVD的最常见方法之一是压缩图像。毕竟,仅可以减少构成图像中红色,绿色和蓝色通道的像素值,结果将是图像不那么复杂但仍包含相同图像内容的图像。让我们尝试使用SVD压缩图像并进行渲染。
我们将使用几个函数来处理图像的压缩。实际上,我们只需要Numpy和PIL库中的Image函数即可完成此操作,因为Numpy具有执行SVD计算的方法:
import numpy
from PIL import Image首先,我们将编写一个函数以加载图像并将其转换为Numpy数组。然后,我们要从图像中选择红色,绿色和蓝色通道:
def load_image(image):
image = Image.open(image)
im_array = numpy.array(image)
red = im_array[:, :, 0]
green = im_array[:, :, 1]
blue = im_array[:, :, 2]
return red, green, blue现在我们有了颜色,我们需要压缩颜色通道。我们可以在所需的颜色通道上调用Numpy的SVD函数开始。然后,我们将创建一个零数组,该矩阵将在矩阵乘法完成后填充。然后,我们指定进行计算时要使用的奇异值限制:
def channel_compress(color_channel, singular_value_limit):
u, s, v = numpy.linalg.svd(color_channel)
compressed = numpy.zeros((color_channel.shape[0], color_channel.shape[1]))
n = singular_value_limit
left_matrix = numpy.matmul(u[:, 0:n], numpy.diag(s)[0:n, 0:n])
inner_compressed = numpy.matmul(left_matrix, v[0:n, :])
compressed = inner_compressed.astype('uint8')
return compressed
red, green, blue = load_image("dog3.jpg")
singular_val_lim = 350之后,如上所述,我们在对角线和U矩阵中的值限制上进行矩阵乘法。这样就得到了左矩阵,然后将其与V矩阵相乘。这应该为我们获取压缩值,然后将其转换为“ uint8″类型:
def compress_image(red, green, blue, singular_val_lim):
compressed_red = channel_compress(red, singular_val_lim)
compressed_green = channel_compress(green, singular_val_lim)
compressed_blue = channel_compress(blue, singular_val_lim)
im_red = Image.fromarray(compressed_red)
im_blue = Image.fromarray(compressed_blue)
im_green = Image.fromarray(compressed_green)
new_image = Image.merge("RGB", (im_red, im_green, im_blue))
new_image.show()
new_image.save("dog3-edited.jpg")
compress_image(red, green, blue, singular_val_lim)我们将使用狗的这张图片来测试SVD压缩:

我们还需要设置将要使用的奇异值限制,现在让我们从600开始:
red, green, blue = load_image("dog.jpg")
singular_val_lim = 350最后,我们可以获得三个颜色通道的压缩值,并使用PIL将其从Numpy数组转换为图像分量。然后,我们只需要将三个通道结合在一起并显示图像即可。该图像应比原始图像小一些并且简单一些:

确实,如果您检查图像的大小,则会注意到压缩后的图像较小,尽管我们也进行了一些有损压缩。您还可以在图像中看到一些噪点。
您可以尝试调整奇异值限制。选择的限制越低,压缩率越大,但是在某些时候会出现图像伪影,并且图像质量会下降:
def compress_image(red, green, blue, singular_val_lim):
compressed_red = channel_compress(red, singular_val_lim)
compressed_green = channel_compress(green, singular_val_lim)
compressed_blue = channel_compress(blue, singular_val_lim)
im_red = Image.fromarray(compressed_red)
im_blue = Image.fromarray(compressed_blue)
im_green = Image.fromarray(compressed_green)
new_image = Image.merge("RGB", (im_red, im_green, im_blue))
new_image.show()
compress_image(red, green, blue, singular_val_lim)线性判别分析
线性判别分析通过将数据从多维图投影到线性图上来进行操作。想到这一点的最简单方法是将两个不同类的数据点填充在一起的图形。假设没有行将数据整齐地分为两类,则可以将二维图形简化为一维图形。然后可以将此一维图形用于希望实现数据点的最佳分离。
当执行LDA时,有两个主要目标:最小化两个类别的方差,以及最大化两个数据类别的均值之间的距离。
为了实现这一点,将在2D图形中绘制一个新轴。这个新轴应根据前面提到的标准将两个数据点分开。创建新轴后,将沿着新轴重新绘制2D图形内的数据点。
LDA执行三个不同的步骤将原始图形移动到新轴。首先,必须计算类别之间的可分离性,这是基于类别均值之间的距离或类别间方差。在下一步中,必须计算类内差异,即不同类的均值和样本之间的距离。最后,必须构建使类间差异最大化的较低维空间。
当类别的手段彼此相距遥远时,LDA最有效。如果分配的方式是共享的,则LDA将无法使用新的线性轴来分隔类。
LDA实施示例
最后,让我们看看如何使用LDA进行降维。注意,除了执行降维之外,LDA还可以用作分类算法。
以下示例将使用Titanic数据集。
让我们开始进行所有必要的导入:
import pandas as pd
import numpy as np
from sklearn.metrics import accuracy_score, f1_score
from sklearn.preprocessing import LabelEncoder, StandardScaler
from sklearn.discriminant_analysis import LinearDiscriminantAnalysis as LDA
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LogisticRegression现在,我们将加载训练数据,将其分为训练集和验证集。
不过,我们需要先做一些数据预处理。让我们放下Name,Cabin和Ticket列,因为他们不携带了很多有用的信息。我们还需要填写缺少的数据,我们将在的情况下,与中值替换Age功能和S在的情况下Embarked功能:
training_data = pd.read_csv("train.csv")
# Let's drop the cabin and ticket columns
training_data.drop(labels=['Cabin', 'Ticket'], axis=1, inplace=True)
training_data["Age"].fillna(training_data["Age"].median(), inplace=True)
training_data["Embarked"].fillna("S", inplace=True)我们还需要对非数字特征进行编码。我们将同时编码Sex和Embarked列。让我们也删除该Name列,因为它似乎不太可能在分类中有用:
encoder_1 = LabelEncoder()
# Fit the encoder on the data
encoder_1.fit(training_data["Sex"])
# Transform and replace the training data
training_sex_encoded = encoder_1.transform(training_data["Sex"])
training_data["Sex"] = training_sex_encoded
encoder_2 = LabelEncoder()
encoder_2.fit(training_data["Embarked"])
training_embarked_encoded = encoder_2.transform(training_data["Embarked"])
training_data["Embarked"] = training_embarked_encoded
# Assume the name is going to be useless and drop it
training_data.drop("Name", axis=1, inplace=True)我们需要缩放值,但是该Scaler工具使用数组,因此要重塑的值需要首先转换为数组。之后,我们可以缩放数据:
# Remember that the scaler takes arrays
ages_train = np.array(training_data["Age"]).reshape(-1, 1)
fares_train = np.array(training_data["Fare"]).reshape(-1, 1)
scaler = StandardScaler()
training_data["Age"] = scaler.fit_transform(ages_train)
training_data["Fare"] = scaler.fit_transform(fares_train)
# Now to select our training and testing data
features = training_data.drop(labels=['PassengerId', 'Survived'], axis=1)
labels = training_data['Survived']现在,我们可以选择训练功能和标签,并用于train_test_split制作训练和验证数据。使用LDA进行分类很容易,您可以像处理Scikit-Learn中的任何其他分类器一样进行处理。
只需将功能拟合到训练数据上,并根据验证/测试数据进行预测即可。然后,我们可以根据实际值打印预测的指标:
X_train, X_val, y_train, y_val = train_test_split(features, labels, test_size=0.2, random_state=27)
model = LDA()
model.fit(X_train, y_train)
preds = model.predict(X_val)
acc = accuracy_score(y_val, preds)
f1 = f1_score(y_val, preds)
print("Accuracy: {}".format(acc))
print("F1 Score: {}".format(f1))这是打印输出:
Accuracy: 0.8100558659217877
F1 Score: 0.734375当涉及到数据转换和降维时,让我们首先对数据运行Logistic回归分类器,这样我们就可以了解降维之前的性能:
logreg_clf = LogisticRegression()
logreg_clf.fit(X_train, y_train)
preds = logreg_clf.predict(X_val)
acc = accuracy_score(y_val, preds)
f1 = f1_score(y_val, preds)
print("Accuracy: {}".format(acc))
print("F1 Score: {}".format(f1))结果如下:
Accuracy: 0.8100558659217877
F1 Score: 0.734375现在,我们将通过为LDA指定许多所需的组件并将模型拟合到特征和标签上来变换数据特征。然后,我们仅转换要素并将其保存到新变量中。让我们打印出原始的和减少的功能:
LDA_transform = LDA(n_components=1)
LDA_transform.fit(features, labels)
features_new = LDA_transform.transform(features)
# Print the number of features
print('Original feature #:', features.shape[1])
print('Reduced feature #:', features_new.shape[1])
# Print the ratio of explained variance
print(LDA_transform.explained_variance_ratio_)这是上面的代码的打印输出:
Original feature #: 7
Reduced feature #: 1
[1.]现在,我们只需使用新功能再次进行训练/测试拆分,然后再次运行分类器,以查看性能如何变化:
X_train, X_val, y_train, y_val = train_test_split(features_new, labels, test_size=0.2, random_state=27)
logreg_clf = LogisticRegression()
logreg_clf.fit(X_train, y_train)
preds = logreg_clf.predict(X_val)
acc = accuracy_score(y_val, preds)
f1 = f1_score(y_val, preds)
print("Accuracy: {}".format(acc))
print("F1 Score: {}".format(f1))Accuracy: 0.8212290502793296
F1 Score: 0.7500000000000001结论
我们已经研究了降维技术的主要方法:主成分分析,奇异值分解和线性判别分析。您可以使用这些统计技术来帮助您的机器学习模型更好地执行,消除过度拟合并协助数据分析。