StandardScaler、MinMaxScaler 和 RobustScaler 技术 – ML
StandardScaler遵循标准正态分布 (SND) 。因此,它使均值 = 0并将数据缩放为单位方差。
MinMaxScaler缩放范围[0, 1]内的所有数据特征,如果数据集中存在负值,则缩放范围[-1, 1]内的所有数据特征。这种缩放压缩了窄范围[0, 0.005]中的所有内点。
在存在异常值的情况下,由于在计算经验均值和标准差时异常值的影响,StandardScaler 不能保证平衡的特征尺度。这导致特征值范围的缩小。
通过使用RobustScaler() ,我们可以删除异常值,然后使用 StandardScaler 或 MinMaxScaler 对数据集进行预处理。
RobustScaler 的工作原理:
班级
sklearn.preprocessing.RobustScaler(
with_centering=真,
with_scaling=真,
quantile_range=(25.0, 75.0),
复制=真,
)
它使用对异常值具有鲁棒性的统计数据来缩放特征。此方法移除中位数并将数据缩放到 1st quartile 和3rd quartile之间的范围内。即,在第 25 个分位数和第 75 个分位数之间。这个范围也称为四分位间距。
然后存储中位数和四分位数范围,以便可以使用变换方法将其用于未来的数据。如果数据集中存在异常值,则中位数和四分位数范围可提供更好的结果,并且优于样本均值和方差。
RobustScaler 使用四分位数范围,因此它对异常值具有鲁棒性。因此其公式如下: 
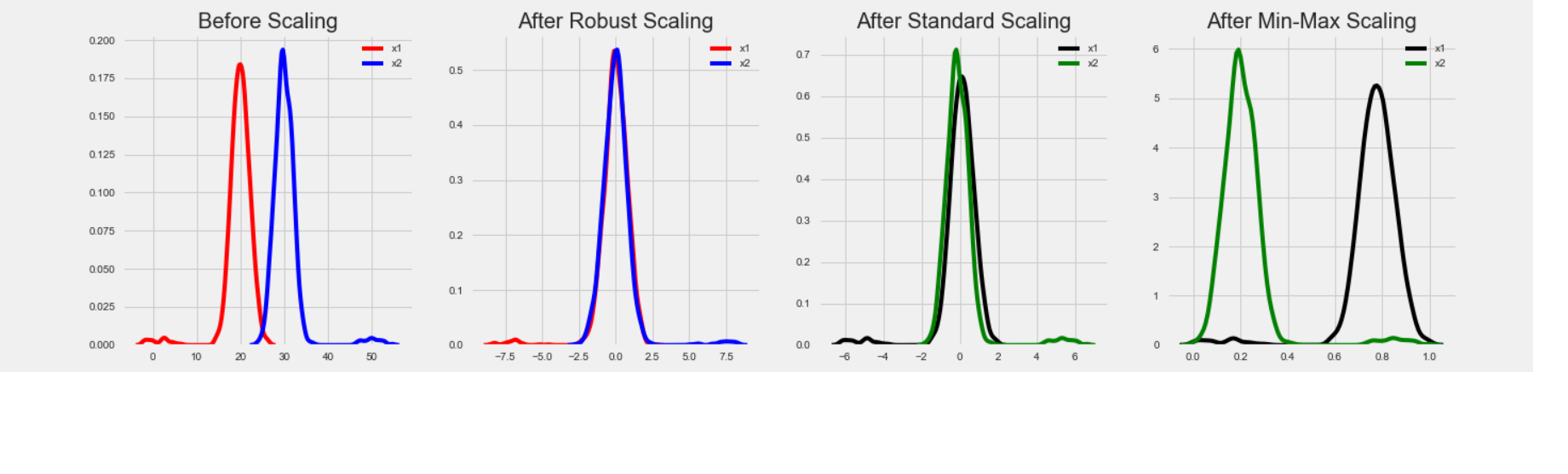
代码:StandardScaler、MinMaxScaler 和 RobustScaler 之间的比较。
Python3
# Importing libraries
import pandas as pd
import numpy as np
from sklearn import preprocessing
import matplotlib
import matplotlib.pyplot as plt
import seaborn as sns % matplotlib inline
matplotlib.style.use('fivethirtyeight')
# data
x = pd.DataFrame({
# Distribution with lower outliers
'x1': np.concatenate([np.random.normal(20, 2, 1000), np.random.normal(1, 2, 25)]),
# Distribution with higher outliers
'x2': np.concatenate([np.random.normal(30, 2, 1000), np.random.normal(50, 2, 25)]),
})
np.random.normal
scaler = preprocessing.RobustScaler()
robust_df = scaler.fit_transform(x)
robust_df = pd.DataFrame(robust_df, columns =['x1', 'x2'])
scaler = preprocessing.StandardScaler()
standard_df = scaler.fit_transform(x)
standard_df = pd.DataFrame(standard_df, columns =['x1', 'x2'])
scaler = preprocessing.MinMaxScaler()
minmax_df = scaler.fit_transform(x)
minmax_df = pd.DataFrame(minmax_df, columns =['x1', 'x2'])
fig, (ax1, ax2, ax3, ax4) = plt.subplots(ncols = 4, figsize =(20, 5))
ax1.set_title('Before Scaling')
sns.kdeplot(x['x1'], ax = ax1, color ='r')
sns.kdeplot(x['x2'], ax = ax1, color ='b')
ax2.set_title('After Robust Scaling')
sns.kdeplot(robust_df['x1'], ax = ax2, color ='red')
sns.kdeplot(robust_df['x2'], ax = ax2, color ='blue')
ax3.set_title('After Standard Scaling')
sns.kdeplot(standard_df['x1'], ax = ax3, color ='black')
sns.kdeplot(standard_df['x2'], ax = ax3, color ='g')
ax4.set_title('After Min-Max Scaling')
sns.kdeplot(minmax_df['x1'], ax = ax4, color ='black')
sns.kdeplot(minmax_df['x2'], ax = ax4, color ='g')
plt.show()输出:
RobustScaler 的参数:
- with_centering: boolean:默认为 True。如果值为 True,则数据在缩放之前居中。当它应用于稀疏矩阵时,变换会引发异常,因为将它们居中需要构建一个密集矩阵,该矩阵通常太大而无法放入内存。
- with_scaling: boolean:默认情况下也设置为 True。它将数据缩放到四分位数范围。
- quantile_range: tuple(q_min, q_max), 0.0 < q_min < q_max < 100.0 :分位数范围用于计算比例。默认情况下,设置如下。默认值: (25.0, 75.0) = (1st quantile, 3rd quantile) = IQR。
- copy: boolean可选参数。默认情况下,它是 True。如果输入已经是 NumPy 数组或 scipy.sparse CSC 矩阵并且如果axis = 1 ,则通过将此参数设置为 False 来避免复制,而是执行就地行规范化。
属性:
- center_:浮点数组:训练集中每个特征的中值。
- scale_:浮点数组:训练集中特征的缩放四分位数范围。