📅 最后修改于: 2020-08-03 05:03:34 🧑 作者: Mango
介绍
如果您是出于娱乐目的而不时开发机器学习模型的机器学习工程师,数据科学家或业余爱好者,那么您很有可能熟悉Tensorflow。
Tensorflow是由Google Brain团队以Python,C++和CUDA编写的开源和免费框架。它用于开发,测试和部署机器学习模型。
最初,Tensoflow并不完全支持多种平台和编程语言,并且对于训练机器学习模型并不是非常快速和有效,但是随着时间的流逝和一些更新,现在Tensorflow被认为是开发的首选框架。 ,训练和部署机器学习模型。
Tensorflow 1.x
Tensorflow 1.x也是该框架的巨大飞跃。它引入了许多新功能,改进的性能和开源贡献。它为TensorFlow引入了高级API,这使得立即构建原型变得非常容易。
它与Keras兼容。但令开发人员感到恼火的主要是,在使用TensorFlow时,它并不想利用Python的简单性。
在TensorFlow中,每个模型都表示为图形,而节点则表示图形中的计算。它是“符号编程”的示例,而Python是“命令式编程”语言。
我不会详细介绍,因为这超出了本文的范围。但是这里的要点是,随着PyTorch的发布(它非常面向命令式编程并利用了Python的动态行为),新手和研究科学家发现PyTorch比Tensorflow更易于理解和学习,而且PyTorch很快就开始受到欢迎。 。
每个Tensorflow开发人员都对Tensorflow和Google Brain团队提出了相同的要求。此外,TensorFlow 1.x经过大量开发,从而产生了许多API,即,tf.layers, tf.contrib.layers, tf.keras开发人员有很多选择可供选择,这导致了冲突。
Tensorflow 2.0的公告
很明显,Tensorflow团队必须解决这些问题,因此他们宣布了Tensorflow 2.0。
这是迈出的重要一步,因为要解决他们必须进行重大更改的所有问题。许多人都面临着另一种学习经历,但是这些改进使它值得再次学习。
在培训阶段,我们将介绍tf.data和数据集,它使我们能够轻松导入和处理数据。然后,我们介绍了在多个CPU,GPU和TPU上进行的分布式培训。对于序列化,我们可以使用SavedModel部署到TensorFlow Hub或TensorFlow Serving,TensorFlow Lite或TensorFlow.JS之类的服务:
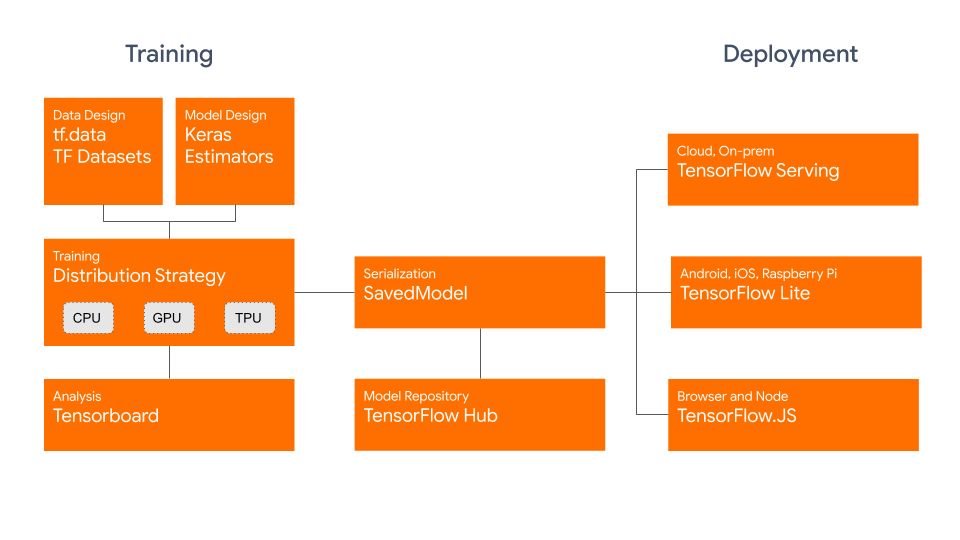
Tensorflow 2.0的新功能
这是Tensorflow 2随附的最重要更新的简短概述。
1.在多个平台上部署模型
Tensorflow总是非常适合生产,但是Tensorflow 2改进了跨多个平台的兼容性和奇偶校验。
它引入了对该SavedModel格式的新平台支持,使我们能够保存Tensorflow模型。这里的新颖之处在于,您可以使用Tensorflow Lite或带有Tensorflow.js的 Node.js 在任何平台上(即,在移动或IoT设备上)部署保存的模型。或者,您可以在生产环境中使用Tensorflow Serving使用。
让我们看一下如何保存已编译的模型:
import os
import tensorflow as tf
# Building the Model
model = tf.keras.Sequential([
tf.keras.layers.Dense(5,actiavtion='relu',input_shape=(16,)),
tf.keras.layers.Dense(1,activation='sigmoid')])
# Compiling the Model
model.compile(loss='binary_crossentropy',optimizer='adam')
# Saving the Model
save_path = path + "/version_number/"
save_path = os.path.join
tf.saved_model.save(model, save_path)然后你去。现在,您可以使用任何上述服务来部署它。
2. Eager
在Tensorflow 2之前,您必须创建一个会话来运行模型。实际上,如果您只想打印变量的值以进行调试,则首先必须创建一个会话,然后在该会话中编写一条print语句。
您必须创建缓慢且无用的占位符,才能将输入数据提供给模型。基本上,在Tensorflow 1.x中,您将首先构建整个图形然后运行它,而不是在运行时构建它。
这让人感觉是静态的和笨拙的,特别是与PyTorch相对,后者允许用户在执行期间创建动态图。
值得庆幸的是,在Tensorflow 2.0中对此进行了修改,使我们热切希望执行。让我们看一下如何在Tensorflow 1.x和2.0中构建图形:
import tensorflow as tf
"""Creating the Graph"""
# Tensorflow 1.x
# Defining two Tensorflow variables
a = tf.Variable(4)
b = tf.Variable(5)
result = tf.multiply(a,b)现在,要访问result变量,我们必须在会话中执行图:
# Creating a session
with tf.Session() as sess:
# Initializing all the Variables
sess.run(tf.global_variables_initializer())
print(sess.run(result))现在,我们可以直接访问它们:
import tensorflow as tf
# Tensorflow 2.0
a = tf.Variable(4)
b = tf.Variable(5)
# No need to create a session
print(float(a*b))3. Keras与Tensorflow集成
Keras是基于Tensorflow构建的神经网络和深度学习API。
大多数人在开始使用Tensorflow或PyTorch之前都是从Keras开始的。它设计用于深度神经网络的快速实验,因此更简单。
在Tensorflow 2.0之前,该库受该库支持,但未集成。现在,它正式是高级API。无需显式安装它,它随Tensorflow一起提供,现在可以通过进行访问tf.keras。
因此,这将导致API清理并删除tf.contrib.layers tf.layers,等等tf.keras。现在是首选API。双方tf.contrib.layers并tf.layers在做同样的事情。有了tf.keras,由于它包含tf.keras.layers模块,因此将具有三重冗余。
该团队还提供了将您的代码从Tensorflow 1.x升级到Tensorflow 2.0 的指南,因为现在已经淘汰了许多较旧的软件包。
4. tf.function装饰器
这也是Tensorflow 2的最令人兴奋的功能之一。@tf.function装饰器允许您将Python函数自动转换为Tensorflow Graphs。
您仍然可以拥有基于图形执行的所有优点,并且摆脱了繁重的基于会话的编程。通过将@tf.function装饰器应用于以下功能:
@tf.function
def multiply(a, b):
return a * b
multiply(tf.ones([2, 2]), tf.ones([2, 2]))如果您想知道,Autograph会自动对其进行补充。它生成的图形具有与我们装饰的功能完全相同的效果。
5.使用分布式计算的培训
Tensorflow 2.0具有改进的性能,可用于使用GPU进行训练。根据团队的说法,此版本比Tensorflow 1.x快3倍。
截至目前,Tensorflow还可以与TPU一起使用。实际上,您可以通过分布式计算方法使用多个TPU和GPU。
您可以在官方指南中阅读有关此内容的更多信息。
6. tf.data和数据集
使用tf.data,现在很容易建立自定义数据管道。无需使用feed_dict。tf.data支持多种类型的输入格式,例如文本,图像,视频,时间序列等等。
它提供了非常干净和有效的输入管道。例如,假设我们要导入带有一些单词的文本文件,这些单词将被预处理并在模型中使用。让我们对大多数NLP问题进行一些经典的预处理。
让我们先阅读文件,将所有单词变成小写,然后将它们分成一个列表:
import numpy as np
text_file = "file.txt"
text = open(text_file,'r').read()
text = text.lower()
text = text.split() 然后,我们要删除所有重复的单词。可以很容易地通过将它们包装在Set,将其转换为List并对其进行排序来完成:
words = sorted(list(set(text)))既然我们已经对独特的单词进行了排序,那么我们将使用它们来制作词汇表。每个单词将分配一个唯一的数字标识符:
vocab_to_int = {word:index for index, word in enumerate(words)}
int_to_vocab = np.array(words) 现在,要将表示单词的整数数组转换为Tensorflow数据集,我们将使用from_tensor_slices()提供的功能tf.data.Dataset:
words_dataset = tf.data.Dataset.from_tensor_slices(words_as_int)现在,我们可以对该数据集执行操作,例如将其分为较小的序列:
seq_len = 50
sequences = words_dataset.batch(seq_len+1,drop_remainder=True)
现在,在训练时,我们可以轻松地从Dataset对象获取批次:
for (batch_n,inp) in enumerate(dataset):另外,您可以直接将现有数据集加载到Dataset对象中:
import tensorflow_datasets as tfds
mnist_data = tfds.load("mnist")
mnist_train, mnist_test = mnist_data["train"], mnist_data["test"]7. tf.keras.Model
一个喜欢的新颖性是通过将keras.Model类子类化来定义您自己的自定义模型。
从PyTorch那里获得了一个提示,它允许开发人员使用自定义类(自定义形成的类,Layer从而改变模型的结构)来创建模型-Tensorflow 2.0(通过Keras)也允许我们定义自定义模型。
让我们创建一个Sequential模型,就像您可能使用Tensorflow 1一样:
# Creating a Model
model = tf.keras.Sequential([
tf.keras.layers.Dense(512,activation='relu',input_shape=(784,)),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(512,activation='relu'),
tf.keras.layers.Dropout(0.2),
tf.keras.layers.Dense(10,activation='softmax')
])现在,Sequential让我们通过使用类的子keras.Model类来创建我们自己的模型,而不是使用模型:
# Creating a Model
class mnist_model(tf.keras.Model):
def __init__(self):
super(mnist_model,self).__init__()
self.dense1 = tf.keras.layers.Dense(512)
self.drop1 = tf.keras.layers.Dropout(0.2)
self.dense2 = tf.keras.layers.Dense(512)
self.drop2 = tf.keras.layers.Dropout(0.2)
self.dense3 = tf.keras.layers.Dense(10)
def call(self,x):
x = tf.nn.relu(self.dense1(x))
x = self.drop1(x)
x = tf.nn.relu(self.dense2(x))
x = self.drop2(x)
x = tf.nn.softmax(self.dense3(x))
return x我们在这里有效地创建了相同的模型,尽管这种方法使我们能够根据需要完全自定义和创建模型。
8. tf.GradientTape
tf.GradientTape使您可以自动计算梯度。使用自定义训练循环时,这很有用。
您可以使用自定义训练循环而不是调用来训练模型model.fit。如果您想对其进行调整,它可以使您更好地控制培训过程。
将提供的自定义训练循环tf.GradientTape与提供的自定义模型配对keras.Model,可以控制模型和从未进行过的训练。
这些很快成为社区中非常喜欢的功能。这是创建带有修饰功能和自定义训练循环的自定义模型的方法:
"""Note: We'll be using the model created in the previous section."""
# Creating the model
model = mnist_model()
# Defining the optimizer and the loss
optimizer = tf.keras.optimizers.Adam(learning_rate=0.001)
loss_object = tf.keras.losses.CategoricalCrossentropy(from_logits=False)
@tf.function
def step(model,x,y):
"""
model: in this case the mnist_model
x: input data in batches
y: True labels """
# Use GradientTape to monitor trainable variables
with tf.GradientTape() as tape:
# Computing predictions
predictions = model(x)
# Calculating Loss
loss = loss_object(y,predictions)
# Extracting all the trainable variables
trainable_variables = model.trainable_variables()
# Computing derivative of loss w.r.t variables/weights
gradients = tape.gradient(loss,trainable_variables)
# Updating the weights
optimizer.apply_gradients(zip(gradients,trainable_variables))
return loss现在,您可以step()通过循环使用批量传递模型和训练数据来调用函数。
结论
随着Tensorflow 2.0的到来,许多挫折已经得到了解决。从广泛的系统支持和新服务到定制模型和培训循环,Tensorflow 2.0还为资深从业者引入了新的学习体验。