在Python中从头开始实现 Radius Neighbors
Radius Neighbors 也是基于实例学习的技术之一。基于实例学习的模型可以泛化到训练示例之外。为此,他们首先存储训练示例。当它遇到一个新实例(或测试实例)时,他们会立即在存储的训练实例和这个新实例之间建立关系,为这个新实例分配一个目标函数值。基于实例的方法有时被称为惰性学习方法,因为它们将学习推迟到遇到新实例进行预测。
这些方法不是为整个空间一次估计假设函数(或目标函数),而是针对每个要预测的新实例进行局部和不同的估计。
半径邻居分类器:
基本假设
- 所有实例都对应于 n 维空间中的点,其中 n 表示任何实例中的特征数。
- 实例的邻居是根据欧几里德距离定义的。
An instance can be represented by < x1, x2, .............., xn >.
Euclidean distance between two instances xa and xb is given by d( xa, xb ) : 
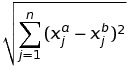
欧几里得距离
它是如何工作的?
Radius Neighbors Classifier 首先存储训练示例。在预测过程中,当它遇到一个新的实例(或测试实例)进行预测时,它会在测试实例的r中心的固定半径内找到来自训练实例的邻居数,其中 r 是用户指定的浮点值。然后将该半径内的训练实例中最常见的类分配给测试实例。
r 的最佳选择是验证测试数据上的错误。
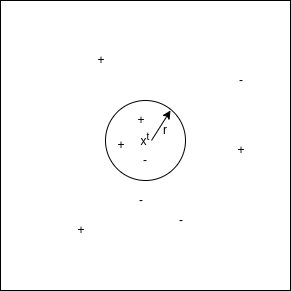
半径邻居分类图形表示
在上图中,“+”表示标记为 1 的训练实例。“-”表示标记为 0 的训练实例。这里我们将测试实例 xt 分类为圆圈内训练实例中最常见的类。这里,r 是用户指定的选择。在上图中,正例在圆圈中占多数,因此 x t被归类为“+”或 1。
伪代码:
- 存储所有训练实例。
- 对每个测试实例重复步骤 3、4 和 5。
- 在测试实例的r中心的固定半径内查找来自训练实例的邻居数。
- 当前测试示例的y_pred = 圆圈内训练实例中最常见的类。
- 转到步骤 2。
执行
此实现中使用的糖尿病数据集可以从链接下载。
它有 8 个特征列,如“年龄”、“葡萄糖”等,以及 108 名患者的目标变量“结果”。因此,在此,我们将创建一个 K-最近邻分类器模型,以预测具有此类信息的患者是否存在糖尿病。
Python3
# Importing libraries
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from scipy.stats import mode
from sklearn.neighbors import RadiusNeighborsClassifier
# Radius Nearest Neighbors Classification
class Radius_Nearest_Neighbors_Classifier() :
def __init__( self, r ) :
self.r = r
# Function to store training set
def fit( self, X_train, Y_train ) :
self.X_train = X_train
self.Y_train = Y_train
# no_of_training_examples, no_of_features
self.m, self.n = X_train.shape
# Function for prediction
def predict( self, X_test ) :
self.X_test = X_test
# no_of_test_examples, no_of_features
self.m_test, self.n = X_test.shape
# initialize Y_predict
Y_predict = np.zeros( self.m_test )
for i in range( self.m_test ) :
x = self.X_test[i]
# find the number of neighbors within a fixed
# radius r of current training example
neighbors = self.find_neighbors( x )
# most frequent class in the circle drawn by current
# training example of fixed radius r
Y_predict[i] = mode( neighbors )[0][0]
return Y_predict
# Function to find the number of neighbors within a fixed radius
# r of current training example
def find_neighbors( self, x ) :
# list to store training examples which will fall in the circle
inside = []
for i in range( self.m ) :
d = self.euclidean( x, self.X_train[i] )
if d <= self.r :
inside.append( self.Y_train[i] )
inside_array = np.array( inside )
return inside_array
# Function to calculate euclidean distance
def euclidean( self, x, x_train ) :
return np.sqrt( np.sum( np.square( x - x_train ) ) )
# driver code
def main() :
# Create dataset
df = pd.read_csv( "diabetes.csv" )
X = df.iloc[:,:-1].values
Y = df.iloc[:,-1:].values
# Splitting dataset into train and test set
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size = 1/3, random_state = 0 )
# Model training
model = Radius_Nearest_Neighbors_Classifier( r = 550 )
model.fit( X_train, Y_train )
model1 = RadiusNeighborsClassifier( radius = 550 )
model1.fit( X_train, Y_train )
# Prediction on test set
Y_pred = model.predict( X_test )
Y_pred1 = model1.predict( X_test )
# measure performance
correctly_classified = 0
correctly_classified1 = 0
# counter
count = 0
for count in range( np.size( Y_pred ) ) :
if Y_test[count] == Y_pred[count] :
correctly_classified = correctly_classified + 1
if Y_test[count] == Y_pred1[count] :
correctly_classified1 = correctly_classified1 + 1
count = count + 1
print("Accuracy on test set by our model : ", (
correctly_classified / count ) * 100 )
print("Accuracy on test set by sklearn model : ", (
correctly_classified / count ) * 100 )
if __name__ == "__main__" :
main()Python3
# Importing libraries
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import RadiusNeighborsRegressor
# Radius Nearest Neighbors Regression
class Radius_Nearest_Neighbors_Regression() :
def __init__( self, r ) :
self.r = r
# Function to store training set
def fit( self, X_train, Y_train ) :
self.X_train = X_train
self.Y_train = Y_train
# no_of_training_examples, no_of_features
self.m, self.n = X_train.shape
# Function for prediction
def predict( self, X_test ) :
self.X_test = X_test
# no_of_test_examples, no_of_features
self.m_test, self.n = X_test.shape
# initialize Y_predict
Y_predict = np.zeros( self.m_test )
for i in range( self.m_test ) :
x = self.X_test[i]
# find the number of neighbors within a fixed
# radius r of current training example
neighbors = self.find_neighbors( x )
# mean of the neighbors in the circle drawn by
# current training example of fixed radius r
Y_predict[i] = np.mean( neighbors )
return Y_predict
# Function to find the number of neighbors within a fixed
# radius r of current training example
def find_neighbors( self, x ) :
# list to store training examples which will fall in the circle
inside = []
for i in range( self.m ) :
d = self.euclidean( x, self.X_train[i] )
if d <= self.r :
inside.append( self.Y_train[i] )
inside_array = np.array( inside )
return inside_array
# Function to calculate euclidean distance
def euclidean( self, x, x_train ) :
return np.sqrt( np.sum( np.square( x - x_train ) ) )
# driver code
def main() :
# Importing dataset
df = pd.read_csv( "salary_data.csv" )
X = df.iloc[:,:-1].values
Y = df.iloc[:,1].values
# Splitting dataset into train and test set
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size = 1/3, random_state = 0 )
# Model training
model = Radius_Nearest_Neighbors_Regression( r = 550 )
model.fit( X_train, Y_train )
model1 = RadiusNeighborsRegressor( radius = 550 )
model1.fit( X_train, Y_train )
# Prediction on test set
Y_pred = model.predict( X_test )
Y_pred1 = model1.predict( X_test )
print( "Real values : ", Y_test[:3] )
print( "Predicted values by our model : ", np.round( Y_pred[:3], 2 ) )
print( "Predicted values by sklearn model : ", np.round( Y_pred1[:3], 2 ) )
if __name__ == "__main__" :
main()输出 :
Accuracy on test set by our model : 61.111111111111114
Accuracy on test set by sklearn model : 61.111111111111114我们的模型和 sklearn 达到的准确度相等,这表明我们模型的正确实现。
注意:以上实现是为了从头开始创建模型,不是为了提高糖尿病数据集的准确性。
半径邻居回归器:
Radius Neighbors Regressor 首先存储训练示例。在预测过程中,当它遇到一个新的实例(或测试实例)进行预测时,它会在测试实例的r中心的固定半径内找到来自训练实例的邻居数,其中 r 是用户指定的浮点值。然后将该半径内的训练实例的平均值分配给测试实例。
r 的最佳选择是验证测试数据上的错误。
伪代码:
- 存储所有训练实例。
- 对每个测试实例重复步骤 3、4 和 5。
- 在测试实例的r中心的固定半径内查找来自训练实例的邻居数。
- 当前测试示例的 y_pred = 圆圈内训练实例的平均值。
- 转到步骤 2。
执行:
此实现中使用的数据集可以从链接下载。
它有 2 列——“ YearsExperience ”和“ Salary ”,适用于一家公司的 30 名员工。因此,在此,我们将创建一个 Radius Neighbors Regression 模型,以了解每个员工的工作年限与其各自工资之间的相关性。
我们创建的模型预测的值与 sklearn 模型为测试集预测的值相同。
代码:
蟒蛇3
# Importing libraries
import pandas as pd
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.neighbors import RadiusNeighborsRegressor
# Radius Nearest Neighbors Regression
class Radius_Nearest_Neighbors_Regression() :
def __init__( self, r ) :
self.r = r
# Function to store training set
def fit( self, X_train, Y_train ) :
self.X_train = X_train
self.Y_train = Y_train
# no_of_training_examples, no_of_features
self.m, self.n = X_train.shape
# Function for prediction
def predict( self, X_test ) :
self.X_test = X_test
# no_of_test_examples, no_of_features
self.m_test, self.n = X_test.shape
# initialize Y_predict
Y_predict = np.zeros( self.m_test )
for i in range( self.m_test ) :
x = self.X_test[i]
# find the number of neighbors within a fixed
# radius r of current training example
neighbors = self.find_neighbors( x )
# mean of the neighbors in the circle drawn by
# current training example of fixed radius r
Y_predict[i] = np.mean( neighbors )
return Y_predict
# Function to find the number of neighbors within a fixed
# radius r of current training example
def find_neighbors( self, x ) :
# list to store training examples which will fall in the circle
inside = []
for i in range( self.m ) :
d = self.euclidean( x, self.X_train[i] )
if d <= self.r :
inside.append( self.Y_train[i] )
inside_array = np.array( inside )
return inside_array
# Function to calculate euclidean distance
def euclidean( self, x, x_train ) :
return np.sqrt( np.sum( np.square( x - x_train ) ) )
# driver code
def main() :
# Importing dataset
df = pd.read_csv( "salary_data.csv" )
X = df.iloc[:,:-1].values
Y = df.iloc[:,1].values
# Splitting dataset into train and test set
X_train, X_test, Y_train, Y_test = train_test_split(
X, Y, test_size = 1/3, random_state = 0 )
# Model training
model = Radius_Nearest_Neighbors_Regression( r = 550 )
model.fit( X_train, Y_train )
model1 = RadiusNeighborsRegressor( radius = 550 )
model1.fit( X_train, Y_train )
# Prediction on test set
Y_pred = model.predict( X_test )
Y_pred1 = model1.predict( X_test )
print( "Real values : ", Y_test[:3] )
print( "Predicted values by our model : ", np.round( Y_pred[:3], 2 ) )
print( "Predicted values by sklearn model : ", np.round( Y_pred1[:3], 2 ) )
if __name__ == "__main__" :
main()
输出:
Real values : [ 37731 122391 57081]
Predicted values by our model : [71022.5 71022.5 71022.5]
Predicted values by sklearn model : [71022.5 71022.5 71022.5]