在Python处理大型 CSV 文件
数据在构建机器学习和 AI 模型方面发挥着关键作用。在当今世界,每个计算设备和传感器都以天文数字的速度生成数据,因此正确处理大量数据非常重要。最常见的数据存储方式之一是以逗号分隔值 (CSV) 的形式。直接导入大量数据会导致内存不足错误,一次读取整个文件会导致内存不足导致系统崩溃。
以下是有效处理 .csv 格式的大型数据文件的几种方法。我们要使用的数据集是gender_voice_dataset。
使用 pandas.read_csv(chunksize)
处理大文件的一种方法是以合理大小的块读取条目,这些条目被读入内存并在读取下一个块之前进行处理。我们可以使用chunk size参数来指定chunk的大小,也就是行数。此函数返回一个迭代器,用于迭代这些块然后处理它们。由于一次仅读取文件的一部分,因此低内存足以处理。
以下是分块读取条目的代码。
chunk = pandas.read_csv(filename,chunksize=...)下面的代码显示了在不使用块的情况下读取数据集所需的时间:
Python3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time = time.time()
df = pd.read_csv("gender_voice_dataset.csv")
e_time = time.time()
print("Read without chunks: ", (e_time-s_time), "seconds")
# data
df.sample(10)Python3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time_chunk = time.time()
chunk = pd.read_csv('gender_voice_dataset.csv', chunksize=1000)
e_time_chunk = time.time()
print("With chunks: ", (e_time_chunk-s_time_chunk), "sec")
df = pd.concat(chunk)
# data
df.sample(10)Python3
# import required modules
import pandas as pd
import numpy as np
import time
from dask import dataframe as df1
# time taken to read data
s_time_dask = time.time()
dask_df = df1.read_csv('gender_voice_dataset.csv')
e_time_dask = time.time()
print("Read with dask: ", (e_time_dask-s_time_dask), "seconds")
# data
dask_df.head(10)输出:
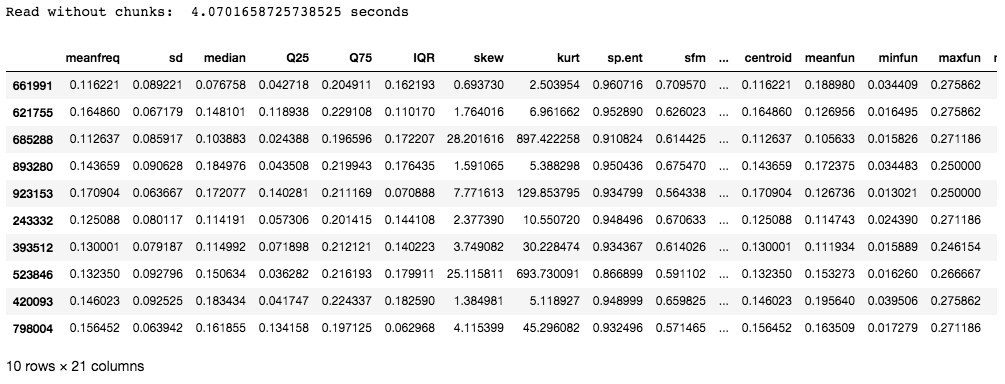
本示例中使用的数据集包含 986894 行和 21 列。花费的时间大约是 4 秒,这可能不会那么长,但是对于具有数百万行的条目,读取条目所花费的时间直接影响模型的效率。
现在,让我们使用块来读取 CSV 文件:
蟒蛇3
# import required modules
import pandas as pd
import numpy as np
import time
# time taken to read data
s_time_chunk = time.time()
chunk = pd.read_csv('gender_voice_dataset.csv', chunksize=1000)
e_time_chunk = time.time()
print("With chunks: ", (e_time_chunk-s_time_chunk), "sec")
df = pd.concat(chunk)
# data
df.sample(10)
输出:

正如您所看到的,与一次性读取整个文件相比,分块所需的时间要少得多。
使用 Dask
Dask 是一个开源Python库,它通过使用现有的库(如 pandas、NumPy 或 sklearn)在Python中包含并行性和可扩展性的特性。
安装:
pip install dask以下是使用dask读取文件的代码:
蟒蛇3
# import required modules
import pandas as pd
import numpy as np
import time
from dask import dataframe as df1
# time taken to read data
s_time_dask = time.time()
dask_df = df1.read_csv('gender_voice_dataset.csv')
e_time_dask = time.time()
print("Read with dask: ", (e_time_dask-s_time_dask), "seconds")
# data
dask_df.head(10)
输出:
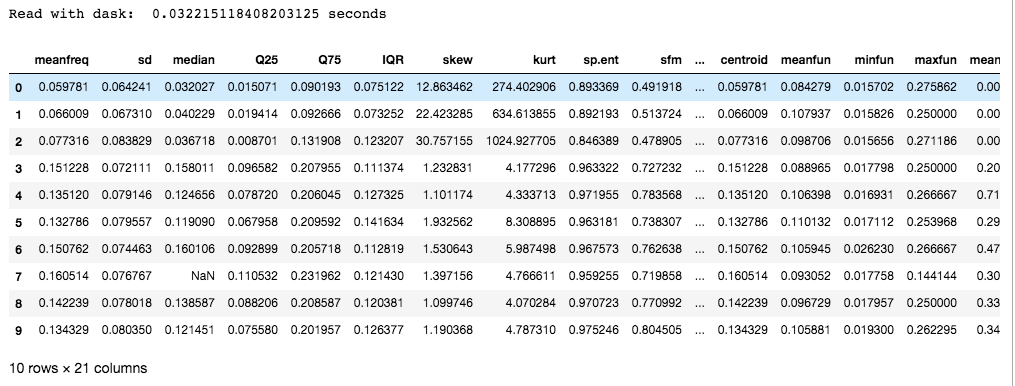
Dask 优于分块,因为它使用多个 CPU 内核或机器集群(称为分布式计算)。除此之外,它还提供了扩展的 NumPy、pandas 和 sci-kit 库来利用并行性。
注意:链接中的数据集大约有 3000 行。出于本文的目的,额外的数据被单独添加,以增加文件的大小。它在原始数据集中不存在。