- PyTorch (1)
- 在 PyTorch 中调整神经网络的学习率(1)
- 在 PyTorch 中调整神经网络的学习率
- 如何在 PyTorch 中调整张量的大小?
- 如何在 PyTorch 中调整张量的大小?(1)
- pytorch 1.7 - Python (1)
- pytorch 逆 - Python (1)
- PyTorch简介|什么是PyTorch(1)
- PyTorch简介|什么是PyTorch
- pytorch 1.7 - Python 代码示例
- pytorch - Python 代码示例
- pytorch 逆 - Python 代码示例
- 技术 (1)
- PyTorch - 任何代码示例
- PyTorch-安装(1)
- PyTorch-安装
- PyTorch-数据集
- PyTorch-数据集(1)
- pytorch - Shell-Bash (1)
- PyTorch安装|如何安装PyTorch
- PyTorch安装|如何安装PyTorch(1)
- 参数 (1)
- C#|可选参数
- 参数 (1)
- 参数化 (1)
- 参数与参数 (1)
- 可选参数 (1)
- C#参数
- 参数 (1)
📅 最后修改于: 2020-11-11 01:10:26 🧑 作者: Mango
Pytorch超参数调整技术
在最后一个主题中,我们训练了Lenet模型和CIFAR数据集。我们发现,我们的LeNet模型可以对大多数图像做出正确的预测,并且发现准确性过高。尽管我们的模型不是训练有素的,但它仍然能够预测大多数验证图像。
由于增加了深度多样性和训练图像固有的复杂性,CIFAR数据集将更加难以分类。
我们与MNIST数据集表现非常出色的LeNet模型现在在准确分类CIFAR数据集方面存在问题。
我们目前正在处理两个主要问题。准确性不够高,网络似乎过度拟合了我们的训练数据。第一个问题可以通过对我们的LeNet模型代码进行各种修改来解决。我们将应用的修改非常取决于大小写,并且对我们的模型容量进行了微调。它通常是一个非常具体的过程,对于每个特定的深度学习任务都是唯一的。
但是,模型的微调很重要,可以显着改善模型性能。我们必须始终尝试修改模型,以查看这些修改如何提高模型的有效性。我们将应用以下修改:
1)第一个修改将重点放在学习率上。 Adam优化器可计算出各个自适应学习率。指定合适的学习率以获得最佳性能仍然很重要。学习率太高通常会导致准确性降低。当涉及到更复杂的数据集时,较低的学习率可以帮助神经网络更有效地学习。
注意:学习率太小会大大降低我们的训练效果。
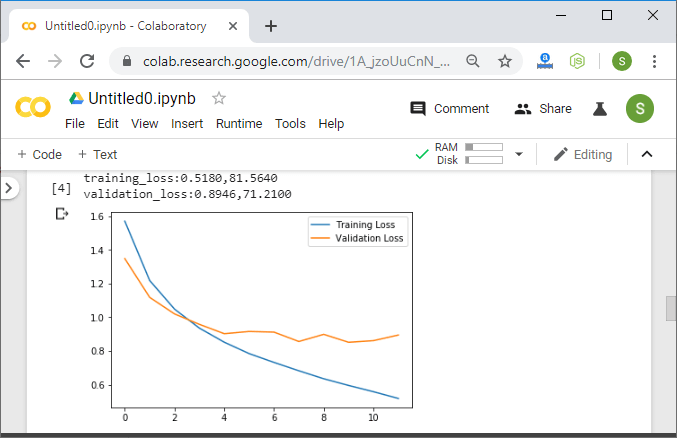
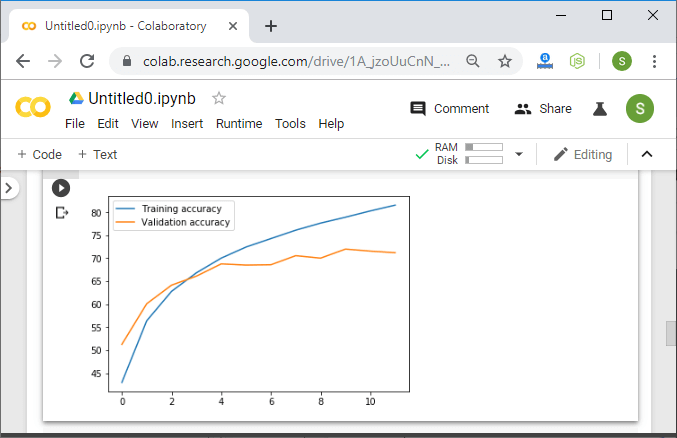
在分析和实证的帮助下,我们得出结论,训练过程相当缓慢,并且从一个时期到下一个时期,训练和验证的准确性没有得到明显提高。
我们将从0.001而不是0.0001设置学习率。
criteron=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.001)
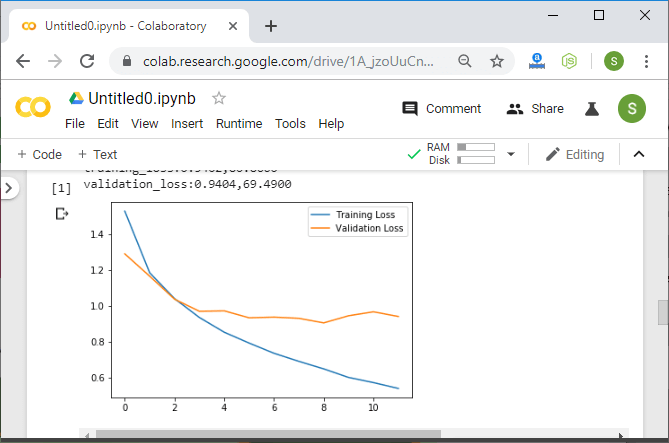
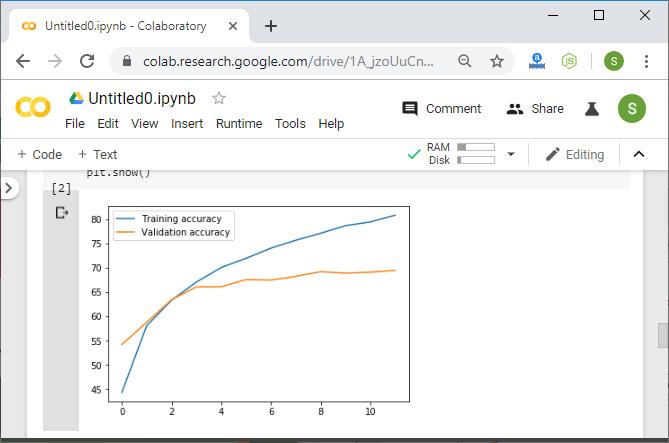
2)第二种修改非常有效。我们将简单地添加更多的层卷积。通过添加更多的卷积,我们的网络可以更有效地提取特征,还可以提高准确性。
注意:定义卷积层的一种通用体系结构是其中每个层将前一层输出的深度加倍的层。
在我们的第一卷积层中,将有3个输入通道,而conv1的深度对应于16个输出通道。然后将其翻倍为32,然后是64,如下所示:
self.conv1=nn.Conv2d(3,16,5,1)
self.conv2=nn.Conv2d(16,32,5,1)
当我们从一个卷积层转到下一个卷积层时,-卷积层的输出深度一直在增加。这样,我们内部增加了过滤器的数量,以提取与转发输入有关的高度复杂的信息。卷积层用于使网络更深,从而提取出越来越复杂的特征。
因此,我们将另一个卷积层conv3设为:
self.conv3=nn.Conv2d(32,64,5,1)
输入到我们完全连接的层中的适当向量将是5乘5,与以前相同,但是输出通道数将是64。
self.fully1=nn.Linear(5*5*64,500)
为了确保一致性,我们还将在正向视图方法中将输出通道的数量更改为:
x=x.view(-1,5*5*64)
初始化第三卷积层后,我们将对它应用relu函数:
x=func.relu(self.conv3(x))
x=func.max_pool2d(x,2,2)
更大的内核意味着更多的参数。我们将使用较小的内核大小来消除过度拟合。我们将使用三个内核大小,这将适合我们的代码。先前在MNIST数据集中,我们在卷积层中未使用任何填充,但是现在我们正在处理一个更复杂的数据集。通过包含填充以确保最大程度地提取特征来保留图像的边缘像素是有意义的。我们将所有卷积层的padding设置为1:
self.conv1=nn.Conv2d(3,16,3,1, padding=1)
self.conv2=nn.Conv2d(16,32,3,1, padding=1)
self.conv3=nn.Conv2d(32,64,3,1, padding=1)
馈入全连接层的最终向量由图像大小决定,该图像大小将在每个最大池化层处减半。图像尺寸将减小为:
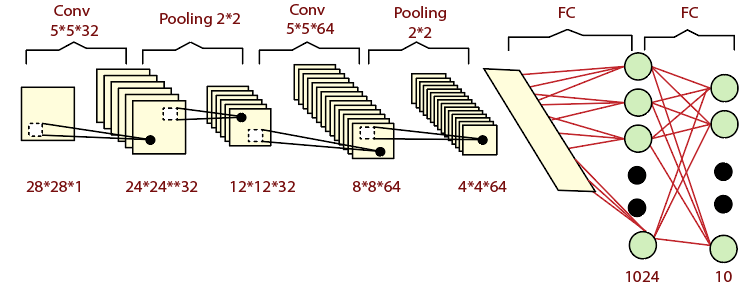
因此,我们将nn.Linear初始化方法更改为:
self.fully1=nn.Linear(4*4*64,500)
同样,我们将前瞻的view方法更改为:
x=x.view(-1,4*4*64)
现在,我们将对其进行培训,它将为我们提供以下预期输出: