- Pytorch图像识别
- Pytorch图像识别(1)
- PyTorch中的图像识别的MNIST数据集
- PyTorch中的图像识别的MNIST数据集(1)
- PyTorch测试(1)
- PyTorch测试
- 图像识别中的图像转换
- 在 pytorch 中保存模型 (1)
- pytorch 加载模型 - Python (1)
- 模型加载 pytorch - Python (1)
- 特征和图像识别 - Python (1)
- 使用TensorFlow进行图像识别
- 使用TensorFlow进行图像识别(1)
- 特征和图像识别 - Python 代码示例
- pytorch 保存模型 - Python (1)
- pytorch 加载模型 - Python 代码示例
- 模型加载 pytorch - Python 代码示例
- pytorch 保存模型 - Python 代码示例
- PyTorch (1)
- 神经网络在图像识别中的实现
- 在 pytorch 中保存模型 - 任何代码示例
- 用于图像识别的卷积块
- 用于图像识别的卷积块(1)
- PyTorch感知器模型|模型设置(1)
- PyTorch感知器模型|模型设置
- 模型 d 或模型 o 点击测试 (1)
- 用于图像识别的神经网络验证
- 用于图像识别的神经网络验证(1)
- pytorch 1.7 - Python (1)
📅 最后修改于: 2020-11-11 01:01:33 🧑 作者: Mango
在PyTorch中测试图像识别模型
在最后一部分中,我们实现了神经网络或创建了对手写数字进行分类的模型。现在,我们通过从网络上获取图像来测试模型。我们使用以下图像:
https://images.homedepot-static.com/productImages/007164ea-d47e-4f66-8d8c-fd9f621984a2/svn/architectural-mailboxes-house-letters-numbers-3585b-5-64_1000.jpg
当您将此链接粘贴到浏览器中时,您将看到数字5的图像:
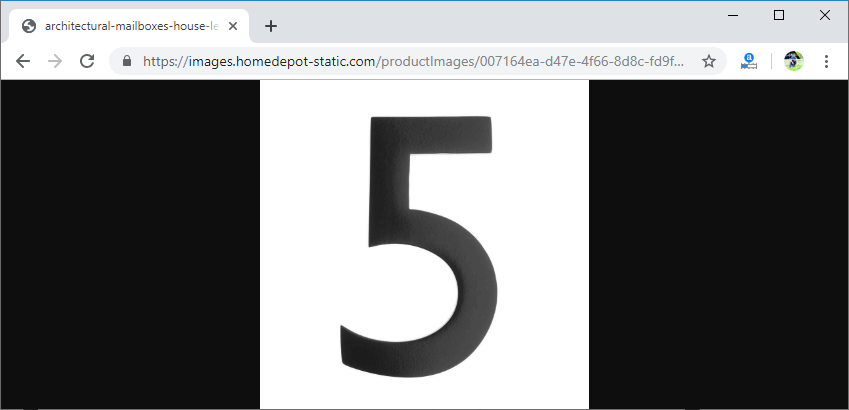
看到这一点之后,我们将意识到它是数字5。现在,我们将尝试使我们的网络对其进行预测。
我们可以通过以下步骤对数字图像进行预测:
步骤1:
第一步,我们将执行GET请求以检索图像数据。要发出GET请求,我们需要将请求导入为:
import requests
现在,我们设置一个变量URL并将链接分配为字符串。
url='https://images.homedepot-static.com/productImages/007164ea-d47e-4f66-8d8c-fd9f621984a2/svn/architectural-mailboxes-house-letters-numbers-3585b-5-64_1000.jpg'
第2步:
在下一步中,我们设置一个变量响应,其值将从请求的get()方法获得。 get()方法将由两个参数组成,即URL和stream,stream将等于true。
response=requests.get(url,stream=True)
第三步:
我们将使用响应的原始内容来获取图像。为此,我们首先必须将图像从PIL(Python图像库)导入。
from PIL import Image
我们使用image的open()方法并将响应的原始内容作为参数传递。从此方法返回的值将分配给名为img的变量,如下所示:
img=Image.open(response.raw)
现在,我们绘制图像以确保一切正常。
plt.imshow(img)
plt.show()
当我们运行它时,它将由于PIL产生错误。我们必须先安装枕头才能运行此代码。我们必须在anaconda命令提示符下运行conda install -c anaconda pillow命令以安装枕头。
运行代码时,它将提供预期的输出。

第四步:
我们需要确保图像与训练后的神经网络学习的图像相对应。我们的图像是1000 * 1000像素,因此我们需要像训练数据中那样将其变成28 * 28灰度图像。在我们训练的图像数据集中,图像具有黑色背景和白色前景,而在上面的图像中则具有白色背景和黑色前景。现在,我们的首要任务是对该图像进行预处理。
我们将使用PIL.ImageOps的invert()方法,并将图像作为参数传递。此方法将反转我们图像的颜色。
img=PIL.ImageOps.invert(img)
该图像是具有三个通道的像素强度值的RGB格式,由于许多原因,这将带来问题。为此,我们必须将该图像转换为二进制黑白图像,并将其转换为:
img=img.convert('1')
我们将以与转换所有其他训练图像相同的方式来转换此图像。我们必须将图像转换为28 * 28像素,因此我们必须在转换后的链组成中添加一个参数调整大小,如下所示:
transform1=transforms.Compose([transforms.Resize((28,28)),transforms.ToTensor(),transforms.Normalize((0.5,),(0.5,))])
img=transform1(img)
现在,我们的图像采用张量的形式,因此我们必须将其更改为numpy数组。在绘制图像之前,我们必须导入PIL.ImageOps,然后将图像绘制为:
import PIL.ImageOps
plt.imshow(im_convert(img))
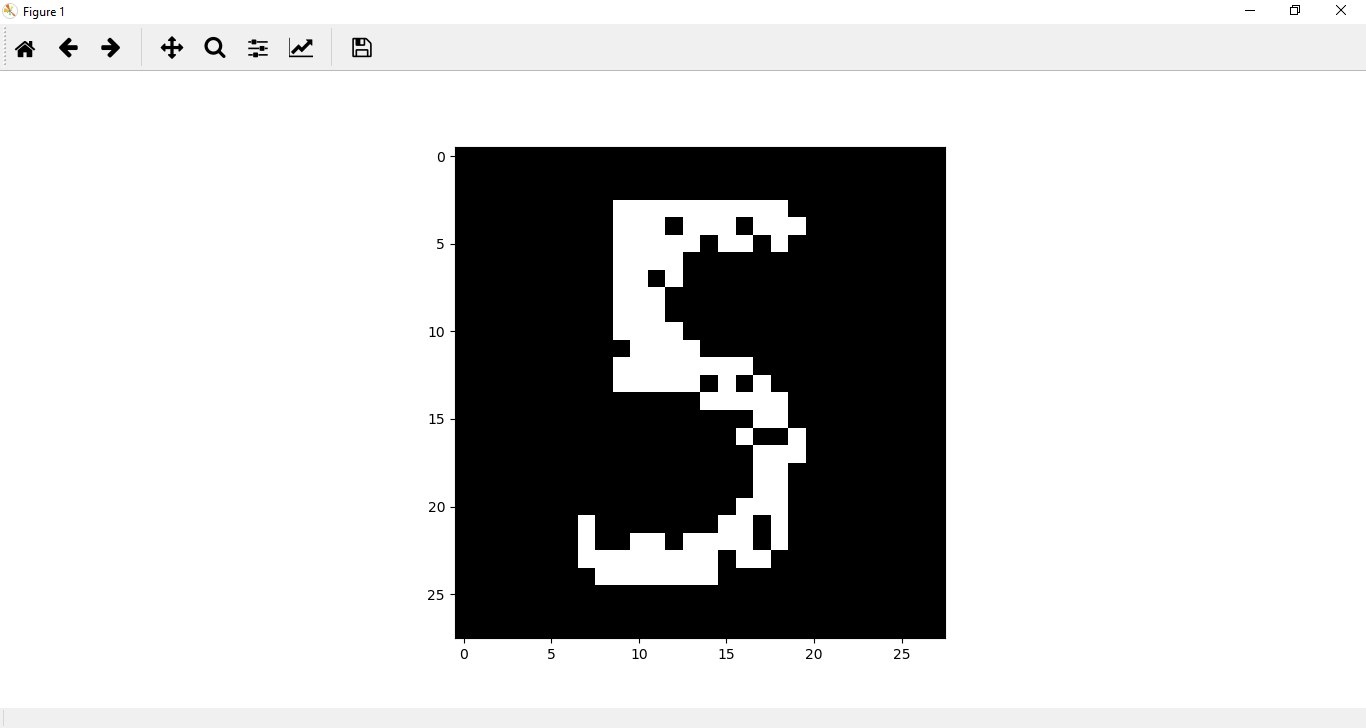
步骤5:
现在,我们将该图像输入到神经网络中进行预测。我们将以与MNIST相同的方式进行操作。
img=img.view(img.shape[0],-1)
output=model(img)
_,pred=torch.max(output,1)
print(pred.item())
它将为我们带来预期的预测:
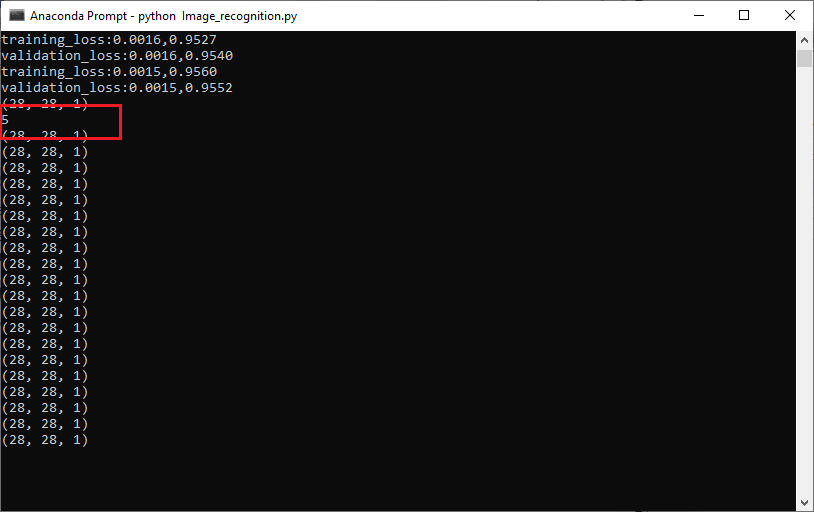
步骤6:
在下一步中,我们包装验证加载程序。它将创建一个对象,使我们一次可以通过可变验证加载程序一个元素。通过一次在dataiter上调用next,我们一次访问一个元素。 next()函数将获取我们的第一批验证数据,并将验证数据分为以下图像和标签:
dataiter=iter(validation_loader)
images,labels=dataiter.next()
为了进行预测,我们必须像以前一样对图像进行整形,并且还需要所有图像的输出和预测。
images_=images.view(images.shape[0],-1)
output=model(images_)
_,preds=torch.max(output,1)
步骤7:
现在,我们将批量绘制图像及其相应的标签。这将借助于plt的图形函数来完成,并且将无花果的大小设置为等于整数25 * 4的元组,这将指定图形的宽度和高度。
fig=plt.figure(figsize=(25,4))
现在,我们从批次中绘制20个MNIST图像。我们使用add_subplot()方法来次要情节添加到当前图,并通过2,图10和IDX作为函数的参数。这里有两个没有行,十个没有列,idx是索引。
ax=fig.add_subplot(2,10,idx+1)
现在,我们将在im_show()函数的帮助下显示图像,并为每个图像绘图指定一个标题:
plt.imshow(im_convert(images[idx]))
ax.set_title("{}({})".format(str(preds[idx].item()),str(labels[idx].item())),color=("green" if preds[idx]==labels[idx] else "red"))
最后调用plt.show(),它将为我们提供预期的结果。
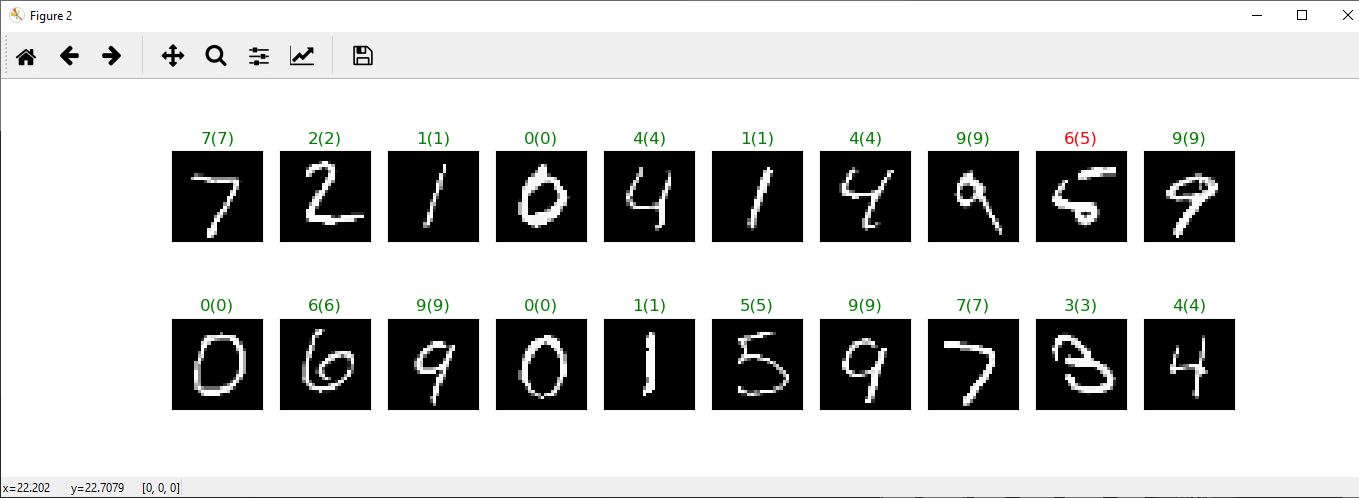
完整的代码:
import torch
import matplotlib.pyplot as plt
import numpy as np
import torch.nn.functional as func
import PIL.ImageOps
from torch import nn
from torchvision import datasets,transforms
import requests
from PIL import Image
transform1=transforms.Compose([transforms.Resize((28,28)),transforms.ToTensor(),transforms.Normalize((0.5,),(0.5,))])
training_dataset=datasets.MNIST(root='./data',train=True,download=True,transform=transform1)
validation_dataset=datasets.MNIST(root='./data',train=False,download=True,transform=transform1)
training_loader=torch.utils.data.DataLoader(dataset=training_dataset,batch_size=100,shuffle=True)
validation_loader=torch.utils.data.DataLoader(dataset=validation_dataset,batch_size=100,shuffle=False)
def im_convert(tensor):
image=tensor.clone().detach().numpy()
image=image.transpose(1,2,0)
print(image.shape)
image=image*(np.array((0.5,0.5,0.5))+np.array((0.5,0.5,0.5)))
image=image.clip(0,1)
return image
dataiter=iter(training_loader)
images,labels=dataiter.next()
fig=plt.figure(figsize=(25,4))
for idx in np.arange(20):
ax=fig.add_subplot(2,10,idx+1)
plt.imshow(im_convert(images[idx]))
ax.set_title([labels[idx].item()])
class classification1(nn.Module):
def __init__(self,input_layer,hidden_layer1,hidden_layer2,output_layer):
super().__init__()
self.linear1=nn.Linear(input_layer,hidden_layer1)
self.linear2=nn.Linear(hidden_layer1,hidden_layer2)
self.linear3=nn.Linear(hidden_layer2,output_layer)
def forward(self,x):
x=func.relu(self.linear1(x))
x=func.relu(self.linear2(x))
x=self.linear3(x)
return x
model=classification1(784,125,65,10)
criteron=nn.CrossEntropyLoss()
optimizer=torch.optim.Adam(model.parameters(),lr=0.0001)
epochs=12
loss_history=[]
correct_history=[]
val_loss_history=[]
val_correct_history=[]
for e in range(epochs):
loss=0.0
correct=0.0
val_loss=0.0
val_correct=0.0
for input,labels in training_loader:
inputs=input.view(input.shape[0],-1)
outputs=model(inputs)
loss1=criteron(outputs,labels)
optimizer.zero_grad()
loss1.backward()
optimizer.step()
_,preds=torch.max(outputs,1)
loss+=loss1.item()
correct+=torch.sum(preds==labels.data)
else:
with torch.no_grad():
for val_input,val_labels in validation_loader:
val_inputs=val_input.view(val_input.shape[0],-1)
val_outputs=model(val_inputs)
val_loss1=criteron(val_outputs,val_labels)
_,val_preds=torch.max(val_outputs,1)
val_loss+=val_loss1.item()
val_correct+=torch.sum(val_preds==val_labels.data)
epoch_loss=loss/len(training_loader.dataset)
epoch_acc=correct.float()/len(training_dataset)
loss_history.append(epoch_loss)
correct_history.append(epoch_acc)
val_epoch_loss=val_loss/len(validation_loader.dataset)
val_epoch_acc=val_correct.float()/len(validation_dataset)
val_loss_history.append(val_epoch_loss)
val_correct_history.append(val_epoch_acc)
print('training_loss:{:.4f},{:.4f}'.format(epoch_loss,epoch_acc.item()))
print('validation_loss:{:.4f},{:.4f}'.format(val_epoch_loss,val_epoch_acc.item()))
url='https://images.homedepot-static.com/productImages/007164ea-d47e-4f66-8d8c-fd9f621984a2/svn/architectural-mailboxes-house-letters-numbers-3585b-5-64_1000.jpg'
response=requests.get(url,stream=True)
img=Image.open(response.raw)
img=PIL.ImageOps.invert(img)
img=img.convert('1')
img=transform1(img)
plt.imshow(im_convert(img))
img=img.view(img.shape[0],-1)
output=model(img)
_,pred=torch.max(output,1)
print(pred.item())
dataiter=iter(validation_loader)
images,labels=dataiter.next()
images_=images.view(images.shape[0],-1)
output=model(images_)
_,preds=torch.max(output,1)
fig=plt.figure(figsize=(25,4))
for idx in np.arange(20):
ax=fig.add_subplot(2,10,idx+1,xticks=[],yticks=[])
plt.imshow(im_convert(images[idx]))
ax.set_title("{}({})".format(str(preds[idx].item()),str(labels[idx].item())),color=("green" if preds[idx]==labels[idx] else "red"))
plt.show()
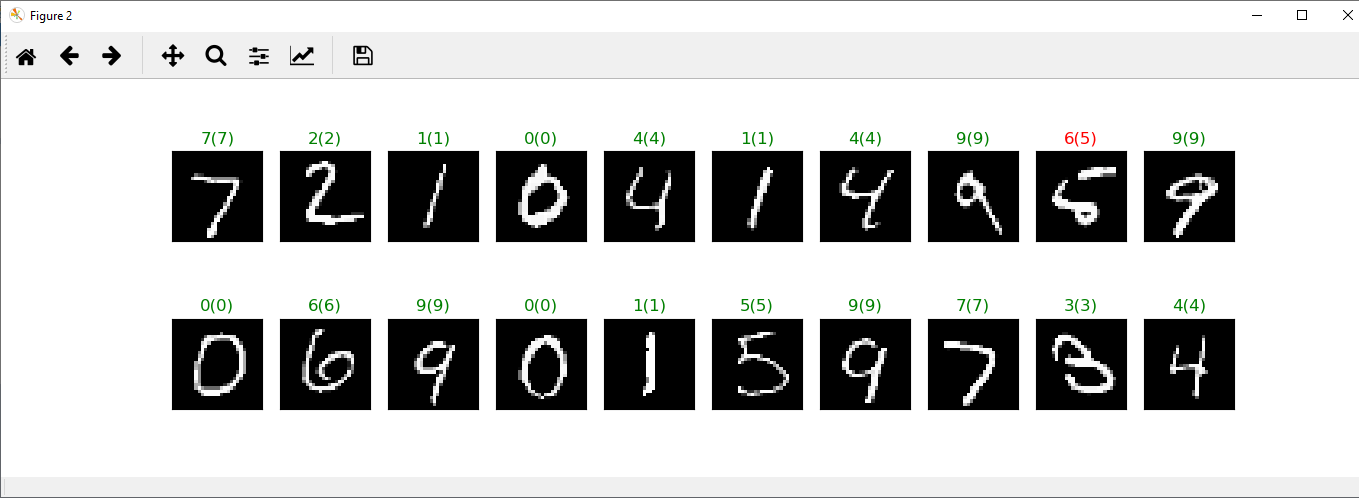
它可以正确预测除一个以外的所有图像,这是我们的深度神经网络所期望的,因为实际上图像分类最好使用卷积神经网络来完成。