- PyTorch-神经网络基础(1)
- PyTorch-神经网络基础
- PyTorch (1)
- C++基础
- C++基础(1)
- pytorch 逆 - Python (1)
- pytorch 1.7 - Python (1)
- 基础 CSS 下拉基础(1)
- 基础 CSS 下拉基础
- PyTorch简介|什么是PyTorch
- PyTorch简介|什么是PyTorch(1)
- pytorch 逆 - Python 代码示例
- pytorch 1.7 - Python 代码示例
- pytorch - Python 代码示例
- Python基础(1)
- Python基础
- PyTorch - 任何代码示例
- PyTorch-安装(1)
- PyTorch-安装
- 基础 CSS 按钮基础
- 基础 CSS 按钮基础(1)
- PyTorch-数据集
- PyTorch-数据集(1)
- pytorch - Shell-Bash (1)
- PyTorch安装|如何安装PyTorch(1)
- PyTorch安装|如何安装PyTorch
- 基础 CSS 分页基础
- 基础 CSS 分页基础(1)
- 基础 CSS 卡(1)
📅 最后修改于: 2020-11-10 06:27:38 🧑 作者: Mango
PyTorch基础
必须了解使用PyTorch所需的所有基本概念。 PyTorch完全基于张量。张量具有要执行的操作。除了这些,还有许多其他概念需要执行任务。
现在,逐一理解所有概念,以深入了解PyTorch。
矩阵或张量
张量是Pytorch的关键组件。可以说PyTorch完全基于张量。用数学术语来说,数字的矩形阵列称为度量。在Numpy库中,这些指标称为ndaaray。在PyTorch中,它被称为Tensor。张量是一个n维数据容器。例如,在PyTorch中,1d-Tensor是一个向量,2d-Tensor是一个度量,3d-Tensor是一个立方体,而4d-Tensor是一个立方体向量。
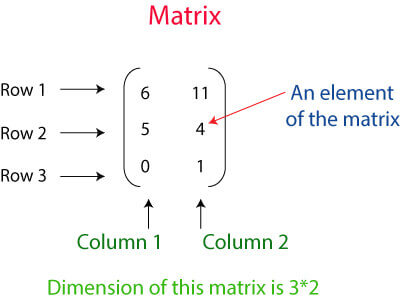
上面的矩阵表示具有三行两列的2D张量。
有三种创建Tensor的方法。每个人都有不同的方式来创建张量。张量创建为:
- 创建PyTorch张量数组
- 创建一个全张量和随机数的张量
- 从numpy数组创建Tensor
让我们看看如何创建张量
将PyTorch张量创建为数组
在这种情况下,您必须首先定义数组,然后将该数组在炬管的Tensor方法中作为参数传递。
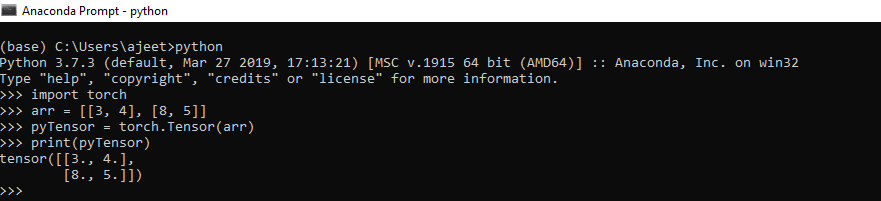
例如
import torch
arr = [[3, 4], [8, 5]]
pyTensor = torch.Tensor(arr)
print(pyTensor)
输出:
tensor ([[3., 4.],[8., 5.]])
用随机数和全部创建一个张量
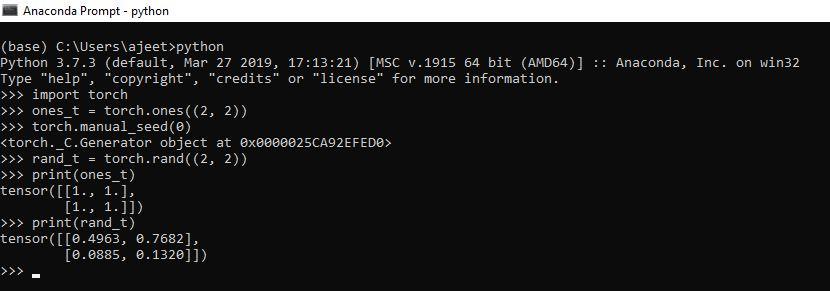
要创建一个随机数Tensor,您必须使用rand()方法,并创建一个包含所有Tensor的Tensor,您必须使用割炬的ones()。为了生成随机数,将对兰德使用火炬的另一种方法,即,manual_seed具有0个参数。
例如
import torch
ones_t = torch.ones((2, 2))
torch.manual_seed(0) //to have same values for random generation
rand_t = torch.rand((2, 2))
print(ones_t)
print(rand_t)
输出:
Tensor ([[1., 1.],[1., 1.]])
tensor ([[0.4963, 0.7682],[0.0885, 0.1320]])
从numpy数组创建张量
要从numpy数组创建张量,我们必须创建一个numpy数组。创建numpy数组后,我们必须将其作为参数传递给from_numpy()。此方法将numpy数组转换为Tensor。
例如
import torch
import numpy as np1
numpy_arr = np1.ones((2, 2))
pyTensor = torch.from_numpy(numpy_arr)
np1_arr_from_Tensor = pyTensor.numpy()
print(np1_arr_from_Tensor)
输出:
[[1. 1.] [1. 1.]]

张量运算
张量类似于数组,因此我们在数组上执行的所有操作也可以适用于张量。
1)调整张量
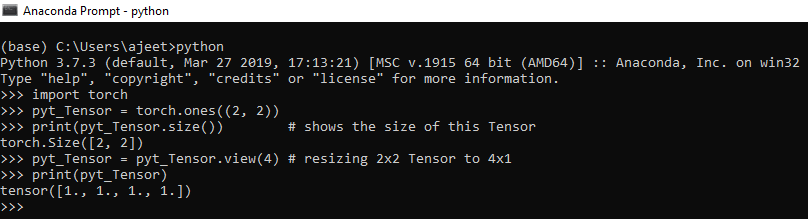
我们可以使用Tensor的size属性来调整Tensor的大小。我们使用Tensor.view()来调整Tensor的大小。调整张量大小意味着将2 * 2维张量转换为4 * 1或将4 * 4维张量转换为16 * 1,依此类推。要printTensor大小,我们使用Tensor.size()方法。
让我们看一个调整张量大小的例子。
import torch
pyt_Tensor = torch.ones((2, 2))
print(pyt_Tensor.size()) # shows the size of this Tensor
pyt_Tensor = pyt_Tensor.view(4) # resizing 2x2 Tensor to 4x1
print(pyt_Tensor)
输出:
torch.Size ([2, 2])
tensor ([1., 1., 1., 1.])
2)数学运算
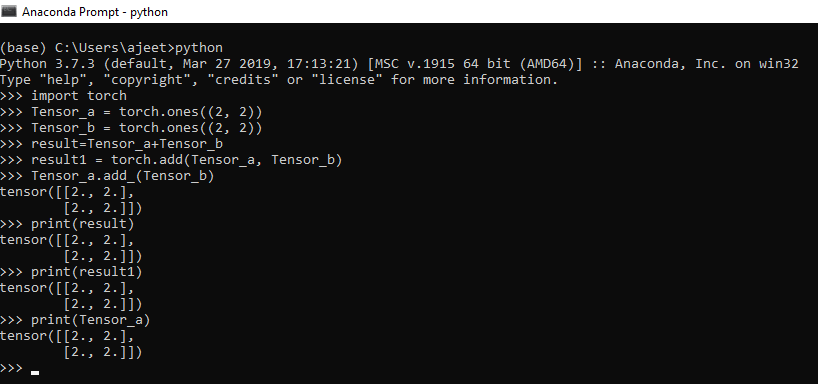
所有数学运算(例如加法,减法,除法和乘法)都可以在Tensor上执行。火炬可以进行数学运算。我们使用torch.add(),torch.sub(),torch.mul()和torch.div()在Tensor上执行操作。
让我们看一个如何执行数学运算的示例:
import numpy as np
import torch
Tensor_a = torch.ones((2, 2))
Tensor_b = torch.ones((2, 2))
result=Tensor_a+Tensor_b
result1 = torch.add(Tensor_a, Tensor_b) //another way of addidtion
Tensor_a.add_(Tensor_b) // In-place addition
print(result)
print(result1)
print(Tensor_a)
输出:
tensor ([[2., 2.], [2., 2.]])
tensor ([[2., 2.], [2., 2.]])
3)均值和标准差
我们可以针对一维或多维计算Tensor的标准偏差。在我们的数学计算中,我们首先要计算平均值,然后对具有平均值的给定数据应用以下公式。
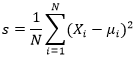
但是在Tensor中,我们可以使用Tensor.mean()和Tensor.std()来找到给定Tensor的偏差和均值。
让我们看一个如何执行的例子。
import torch
pyTensor = torch.Tensor([1, 2, 3, 4, 5])
mean = pyt_Tensor.mean(dim=0) //if multiple rows then dim = 1
std_dev = pyTensor.std(dim=0) // if multiple rows then dim = 1
print(mean)
print(std_dev)
输出:
tensor (3.)
tensor (1.5811)

变量和渐变
软件包的中心类是autograd.variable。它的主要任务是包装张量。它支持几乎所有在其上定义的操作。您可以调用.backword()并仅在完成计算后才计算所有梯度。
通过.data属性,您可以访问行Tensor,而此变量的梯度累积到.grad中。
在深度学习中,梯度计算是关键。变量用于计算PyTorch中的梯度。简单来说,变量只是具有张数计算功能的Tensors的包装。
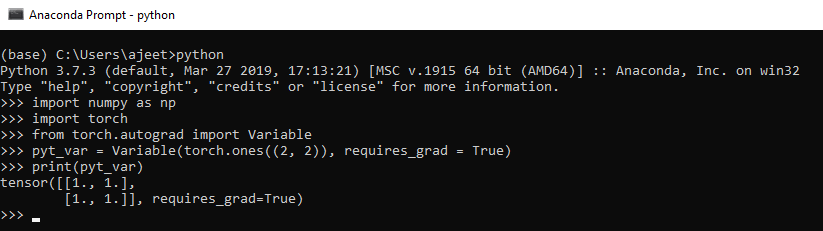
以下是用于管理变量的Python代码。
import numpy as np
import torch
from torch.autograd import Variable
pyt_var = Variable(torch.ones((2, 2)), requires_grad = True)
上面的代码与Tensors的行为相同,因此我们可以以相同的方式应用所有操作。
让我们看看如何在PyTorch中计算梯度。
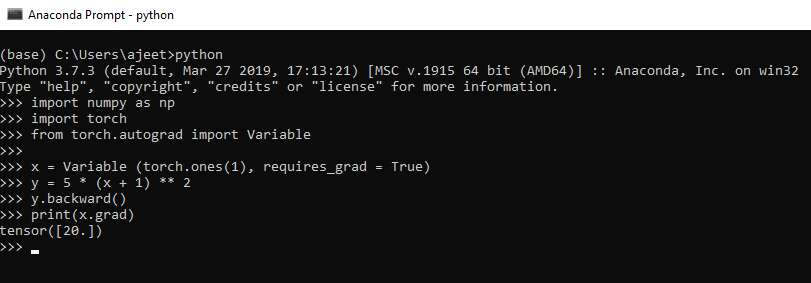
例
import numpy as np
import torch
from torch.autograd import Variable
// let's consider the following equation
// y = 5(x + 1)^2
x = Variable (torch.ones(1), requires_grad = True)
y = 5 * (x + 1) ** 2 //implementing the equation.
y.backward() // calculate gradient
print(x.grad) // get the gradient of variable x
# differentiating the above mentioned equation
// => 5(x + 1)^2 = 10(x + 1) = 10(2) = 20
输出:
tensor([20.])