使用 Pandas 构建推荐引擎
在本文中,我们将学习如何使用 Pandas 从头开始构建一个基本的推荐引擎。
使用 Pandas 构建电影推荐引擎
推荐引擎或推荐系统或推荐系统是根据每个用户的喜好预测或过滤偏好的系统。推荐系统通过协同过滤或基于内容的过滤来监督提供建议索引。
推荐引擎是机器学习中最流行和广泛使用的应用之一。电子商务网站、Netflix、Amazon Prime 等几乎所有大型科技公司都使用推荐引擎向用户推荐合适的商品或电影。它基于相似类型的用户更有可能对相似的搜索项或实体具有相似评级的直觉。
现在让我们开始使用 pandas 创建我们非常基本且简单的推荐引擎。让我们专注于提供一个简单的推荐引擎,通过基于相关性和评级数量(在本例中为电影)呈现与某个对象最相似的事物。它只是告诉哪些电影被认为等同于用户的电影选择。
下载文件:.tsv 文件、Movie_Id_Titles.csv。
基于流行度的过滤
基于流行度的过滤是构建推荐系统的最基本但不是那么有用的过滤技术之一。它基本上过滤掉了最流行的项目并隐藏了其余的项目。例如,在我们的电影数据集中,如果一部电影被大多数用户评分,这意味着它被如此多的用户观看并且现在很流行。所以只有那些评分最高的电影才会被推荐系统推荐给用户。缺乏个性化,因为它对用户的某些特定品味不敏感。
例子:
首先,我们将导入Python的 pandas 库,借助它我们将创建推荐引擎。然后我们从下面的代码中的给定路径加载数据集,并向其中添加列名。
Python3
# import pandas library
import pandas as pd
# Get the column names
col_names = ['user_id', 'item_id', 'rating', 'timestamp']
# Load the dataset
path = 'https://media.geeksforgeeks.org/wp-content/uploads/file.tsv'
ratings = pd.read_csv(path, sep='\t', names=col_names)
# Check the head of the data
print(ratings.head())
# Check out all the movies and their respective IDs
movies = pd.read_csv(
'https://media.geeksforgeeks.org/wp-content/uploads/Movie_Id_Titles.csv')
print(movies.head())
# We merge the data
movies_merge = pd.merge(ratings, movies, on='item_id')
movies_merge.head()Python3
pop_movies = movies_merge.groupby("title")
pop_movies["user_id"].count().sort_values(
ascending=False).reset_index().rename(
columns={"user_id": "score"})
pop_movies['Rank'] = pop_movies['score'].rank(
ascending=0, method='first')
pop_moviesPython3
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.barh(pop_movies['title'].head(6),
pop_movies['score'].head(6),
align='center',
color='RED')
plt.xlabel("Popularity")
plt.title("Popular Movies")
plt.gca().invert_yaxis()Python3
# import pandas library
import pandas as pd
# Get the column names
col_names = ['user_id', 'item_id',
'rating', 'timestamp']
# Load the dataset
path = 'https://media.geeksforgeeks.org/\
wp-content/uploads/file.tsv'
ratings = pd.read_csv(path, sep='\t',
names=col_names)
# Check the head of the data
print(ratings.head())
# Check out all the movies and their respective IDs
movies = pd.read_csv(
'https://media.geeksforgeeks.org/\
wp-content/uploads/Movie_Id_Titles.csv')
print(movies.head())Python3
movies_merge = pd.merge(ratings, movies,
on='item_id')
movies_merge.head()Python3
print(movies_merge.groupby('title')[
'rating'].mean().sort_values(
ascending=False).head())
print(movies_merge.groupby('title')[
'rating'].count().sort_values(
ascending=False).head())Python3
ratings_mean_count_data = pd.DataFrame(
movies_merge.groupby('title')['rating'].mean())
ratings_mean_count_data['rating_counts'] = pd.DataFrame(
movies_merge.groupby('title')['rating'].count())
ratings_mean_count_dataPython3
user_rating = movies_merge.pivot_table(
index='user_id', columns='title', values='rating')
user_rating.head()Python3
Star_Wars_ratings = user_rating['Star Wars (1977)']
Star_Wars_ratings.head(15)Python3
movies_like_Star_Wars = user_rating.corrwith(Star_Wars_ratings)
corr_Star_Wars = pd.DataFrame(movies_like_Star_Wars,
columns=['Correlation'])
corr_Star_Wars.dropna(inplace=True)
corr_Star_Wars.head(10)
corr_Star_Wars.sort_values('Correlation',
ascending=False).head(25)Python3
corr_Star_Wars_count = corr_Star_Wars.join(
ratings_mean_count_data['rating_counts'])Python3
corr_Star_Wars_count[corr_Star_Wars_count[
'rating_counts'] > 100].sort_values(
'Correlation', ascending=False).head()
corr_Star_Wars_count = corr_Star_Wars_count.reset_index()
corr_Star_Wars_countPython3
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.barh(corr_Star_Wars_count['title'].head(10),
abs(corr_Star_Wars_count['Correlation'].head(10)),
align='center',
color='red')
plt.xlabel("Popularity")
plt.title("Top 10 Popular Movies")
plt.gca().invert_yaxis()输出
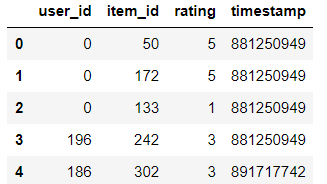
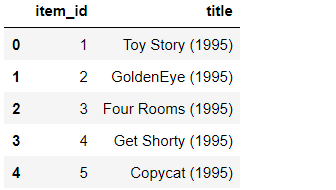
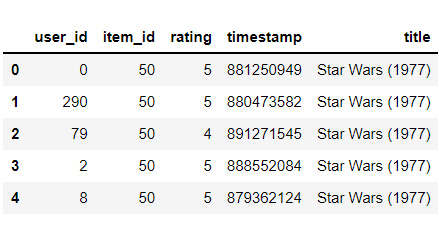
现在我们将根据电影的收视率对电影进行排名。当我们在做基于流行度的过滤时,被更多用户观看的电影会有更多的评分。
Python3
pop_movies = movies_merge.groupby("title")
pop_movies["user_id"].count().sort_values(
ascending=False).reset_index().rename(
columns={"user_id": "score"})
pop_movies['Rank'] = pop_movies['score'].rank(
ascending=0, method='first')
pop_movies
输出
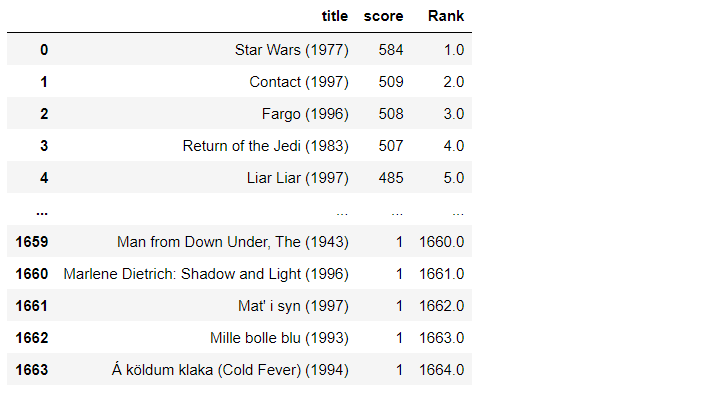
然后我们可视化评分最高的前 10 部电影:
Python3
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.barh(pop_movies['title'].head(6),
pop_movies['score'].head(6),
align='center',
color='RED')
plt.xlabel("Popularity")
plt.title("Popular Movies")
plt.gca().invert_yaxis()
输出
协同过滤
基于用户的过滤:
这些技术向匹配用户选择的用户建议结果。我们可以应用 Pearson 相关或余弦相似度来估计两个用户之间的相似度。在基于用户的协同过滤中,我们定位用户之间的相似度或相似度得分。协同过滤考虑了质量的强度。例如,如果很多人同时看电子书 A 和 B,而新用户只看书 B,那么推荐引擎也会建议用户阅读书 A。
基于项目的协同过滤:
基于项目的协同过滤不是计算各个用户之间的相似度,而是根据他们与目标用户排名的项目的相似度来建议项目。同样,可以使用 Pearson Correlation 或 Cosine Similarity 计算相似度。例如,如果用户 A 喜欢电影 P,并且新用户 B 与 A 相似,那么推荐器将向用户 B 推荐电影 P。
下面的代码演示了基于用户项的协同过滤。
例子:
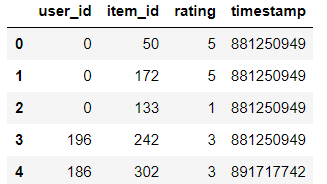
首先,我们将导入Python的 pandas 库,借助它我们将创建推荐引擎。然后我们从下面的代码中的给定路径加载数据集,并向其中添加列名。
Python3
# import pandas library
import pandas as pd
# Get the column names
col_names = ['user_id', 'item_id',
'rating', 'timestamp']
# Load the dataset
path = 'https://media.geeksforgeeks.org/\
wp-content/uploads/file.tsv'
ratings = pd.read_csv(path, sep='\t',
names=col_names)
# Check the head of the data
print(ratings.head())
# Check out all the movies and their respective IDs
movies = pd.read_csv(
'https://media.geeksforgeeks.org/\
wp-content/uploads/Movie_Id_Titles.csv')
print(movies.head())
输出

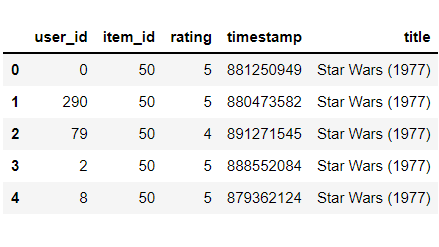
现在我们根据item_id合并两个数据集,item_id 是两者的共同主键。
Python3
movies_merge = pd.merge(ratings, movies,
on='item_id')
movies_merge.head()
输出
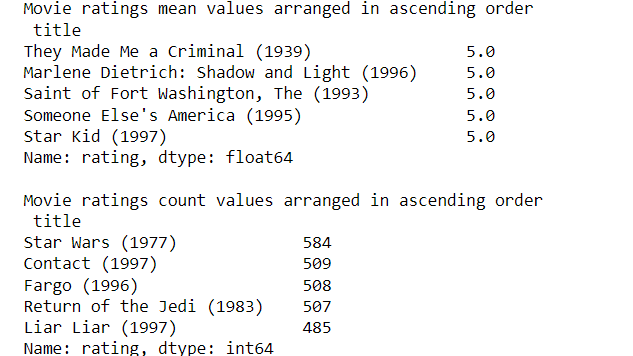
在这里,我们计算每部电影的评分数的平均值。然后我们计算每部电影的评分数。正如我们在输出中看到的那样,我们按升序对它们进行排序。
Python3
print(movies_merge.groupby('title')[
'rating'].mean().sort_values(
ascending=False).head())
print(movies_merge.groupby('title')[
'rating'].count().sort_values(
ascending=False).head())
输出
现在我们创建一个名为rating_mean_count_data的新数据框,并在每个电影标题旁边添加新的评分平均值和评分计数列,因为这两个参数是过滤给用户的最佳建议所必需的。
Python3
ratings_mean_count_data = pd.DataFrame(
movies_merge.groupby('title')['rating'].mean())
ratings_mean_count_data['rating_counts'] = pd.DataFrame(
movies_merge.groupby('title')['rating'].count())
ratings_mean_count_data
输出
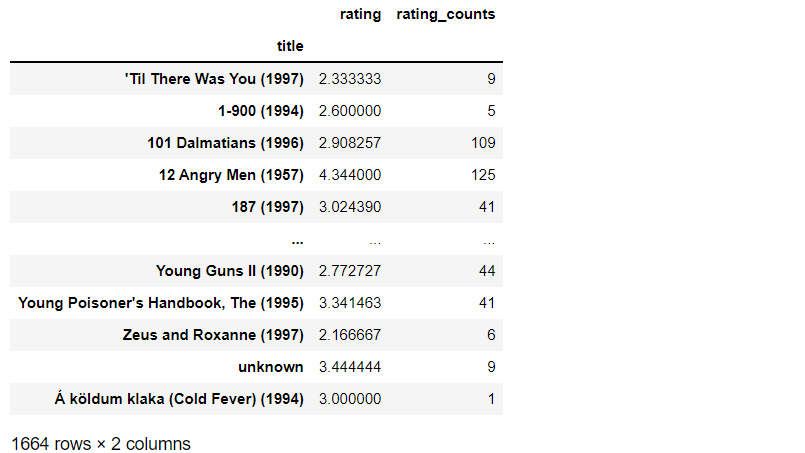
在新创建的数据框中,我们可以看到电影以及收视率的平均值和收视率的数量。现在我们要创建一个矩阵来查看每个用户对每部电影的评分。为此,我们将执行以下代码。
Python3
user_rating = movies_merge.pivot_table(
index='user_id', columns='title', values='rating')
user_rating.head()
输出
在这里,每一列都包含特定电影的所有用户的所有评分,使我们可以轻松找到我们选择的电影的评分。
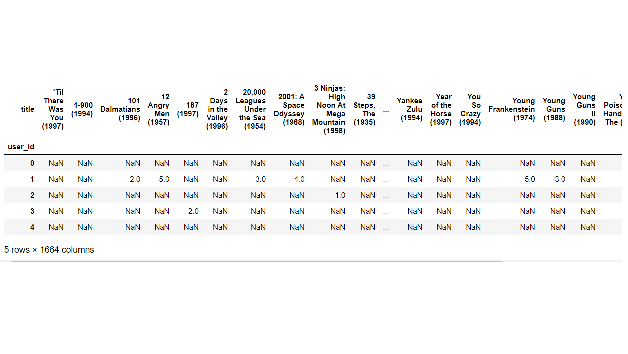
在这里,每一列都包含特定电影的所有用户的所有评分,使我们可以轻松找到我们选择的电影的评分。
因此,我们将看到 Star Wars (1977) 的收视率,因为它的收视率最高。由于我们想找到收视率最高的电影之间的相关性,这将是一个好方法。我们将看到前 25 个评级。
Python3
Star_Wars_ratings = user_rating['Star Wars (1977)']
Star_Wars_ratings.head(15)
输出

现在我们将使用corrwith()函数找到与Star Wars(1977)相关的电影。接下来,我们将相关值存储在名为corr_Star_Wars的新数据帧中的Correlation列下。我们从新数据集中删除了 NaN 值。
我们使用参数“ascending=False”以升序显示与星球大战(1977)高度相关的前 10 部电影。
Python3
movies_like_Star_Wars = user_rating.corrwith(Star_Wars_ratings)
corr_Star_Wars = pd.DataFrame(movies_like_Star_Wars,
columns=['Correlation'])
corr_Star_Wars.dropna(inplace=True)
corr_Star_Wars.head(10)
corr_Star_Wars.sort_values('Correlation',
ascending=False).head(25)
输出
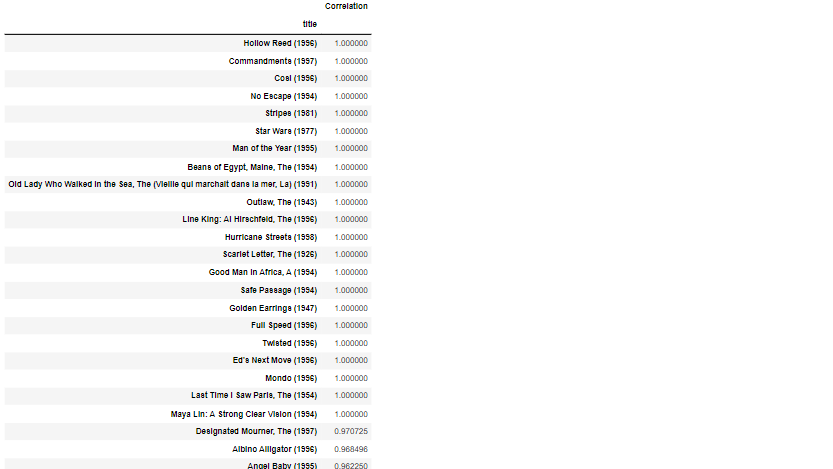
从上面的输出可以看出,与《星球大战》(1977)高度相关的电影并不都是著名的和知名的。
在某些情况下,只有一个用户观看特定电影并给予 5 星评级。在这种情况下,它不会是一个有效的评级,因为没有其他用户看过它。
因此,仅相关性可能不是过滤掉最佳建议的好指标。因此,我们将 rating_counts 列添加到数据框中,以说明评分数量和相关性。
Python3
corr_Star_Wars_count = corr_Star_Wars.join(
ratings_mean_count_data['rating_counts'])
我们假设值得一看的电影至少有一些评分大于 100。所以下面的代码过滤掉了来自 100 多个用户评分的最相关的电影。
Python3
corr_Star_Wars_count[corr_Star_Wars_count[
'rating_counts'] > 100].sort_values(
'Correlation', ascending=False).head()
corr_Star_Wars_count = corr_Star_Wars_count.reset_index()
corr_Star_Wars_count
输出

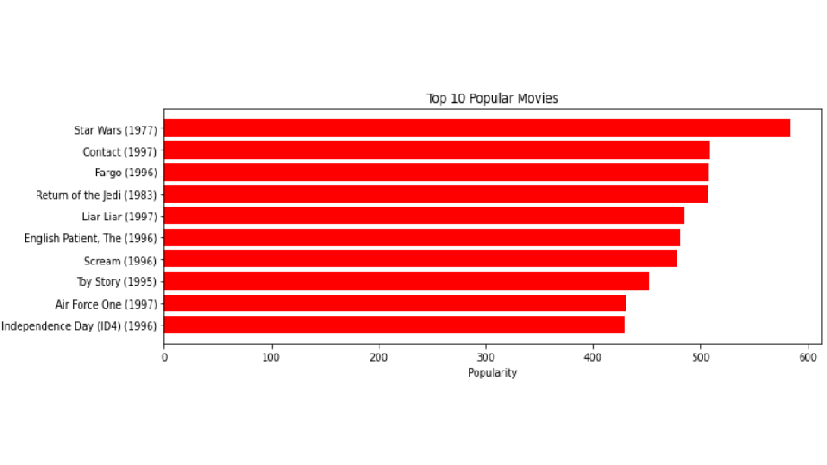
我们可以更好地可视化看到最终的推荐电影集
Python3
import matplotlib.pyplot as plt
plt.figure(figsize=(12, 4))
plt.barh(corr_Star_Wars_count['title'].head(10),
abs(corr_Star_Wars_count['Correlation'].head(10)),
align='center',
color='red')
plt.xlabel("Popularity")
plt.title("Top 10 Popular Movies")
plt.gca().invert_yaxis()
输出
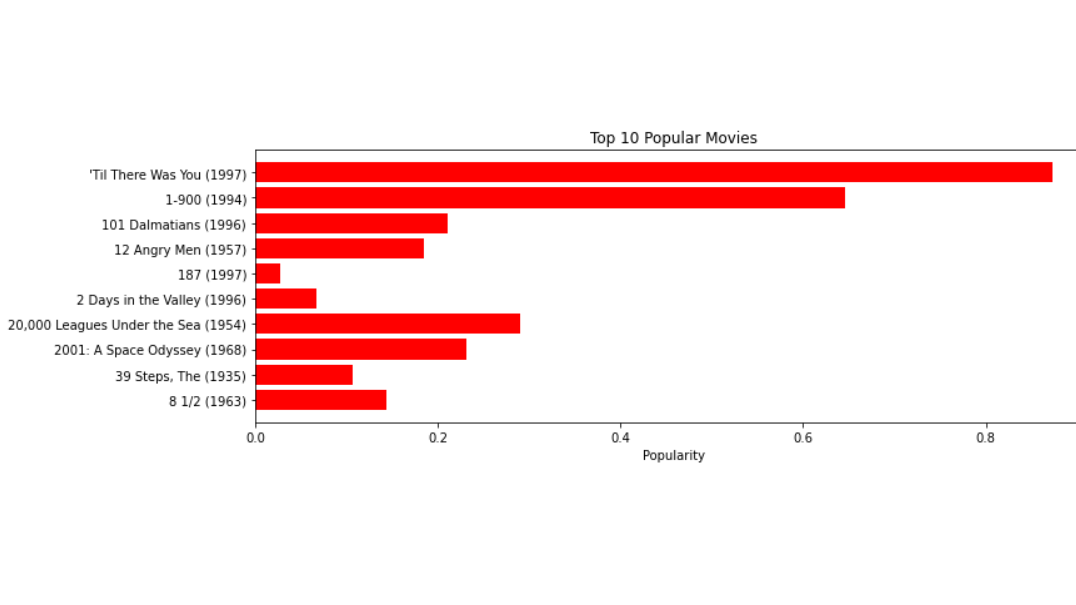
因此,以上电影将推荐给刚看完或看过《星球大战》(1977)的用户。这样,我们就可以用 pandas 构建一个非常基础的推荐系统。对于实时推荐引擎,pandas 肯定无法满足需求。为此,我们将不得不实施复杂的机器学习算法和框架。