Hive带有各种“One Shot”命令,用户可以通过Hive CLI(命令行界面)使用这些命令,而无需进入Hive shell 来执行一个或多个以分号分隔的查询。 Hive CLI 提供多个选项,为用户提供各种功能。我们将讨论各种模式及其功能以及如何在Hive使用它们。要执行以下实现,请确保Hive已启动。
按照以下步骤启动配置单元
第 1 步:启动所有 Hadoop 守护进程
start-dfs.sh # this will start namenode, datanode and secondary namenode
start-yarn.sh # this will start node manager and resource manager
jps # To check running daemons第 2 步:启动Hive
hive
让我们讨论一下 hive one-shot 命令
-e 选项/模式
每当用户要求在Hive CLI 上运行单个或多个查询(用分号分隔)并在查询被触发时立即终止Hive shell,就可以使用Hive的-e选项来启用此功能。执行以下练习以了解其实现。
创建表
CREATE TABLE IF NOT EXISTS student_details(
name STRING,
marks FLOAT)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY ',';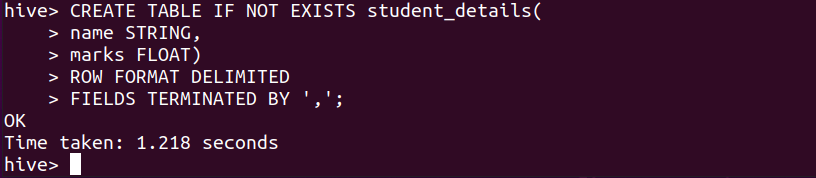
加载数据到表
数据以 CSV 格式提供

LOAD DATA LOCAL INPATH '/home/dikshant/Documents/data.csv' INTO TABLE student_details;
现在按’ ctrl+d ‘退出hive shell。
如果您的要求是在查询显示其结果后立即终止 hive shell,请在 CLI(命令行界面)上使用以下 hive one-shot 命令。
句法:
hive -e ""; hive -e ""; hive -e "";........... 命令
hive -e "select * from student_details";在下面的输出中,我们可以观察到,一旦查询执行完成,hive shell 就会自动终止。

同样,我们可以使用分号分隔的多个查询,如下所示。
hive -e "select name from student_details"; hive -e "select * from student_details LIMIT 1";上述查询的输出:

-S 选项/模式
-S 选项允许用户将 hive CLI 查询的结果存储在文件中。 -S 删除了我们在 CLI 上看到的所有不必要的详细信息,例如所用时间、 Hive会话信息或任何其他信息。当我们想要将查询的干净结果存储在文件中时,该功能非常有用。
句法:
hive -S -e "" > /path/file-name; 我们在路径旁边提供的任何文件名都将由 hive 自动创建并存储我们的查询结果。确保您提供的路径是您的本地系统,而不是 HDFS(Hadoop 分布式文件系统),因为Hive将其输出写入“Stdout”,并且 shell 始终将其重定向到本地路径。
命令:
hive -S -e "select * from student_details" > /home/dikshant/Desktop/query_result.csv;
我们可以使用 hive SET 命令覆盖现有的 hive 属性(不能覆盖环境变量)或显示包含系统和环境变量的 hive 的配置属性。也可以使用 hive 中的 SET 命令检查分离的属性。
命令:
hive -S -e "SET" | grep warehouse;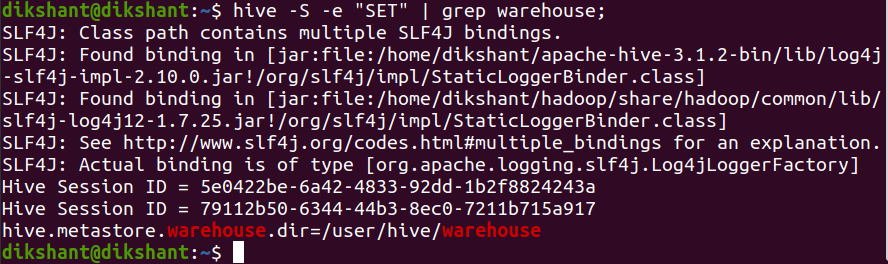
上述命令将显示内部或托管表的内部仓库位置。