Hadoop 分布式文件系统,即 HDFS 用于在 Hadoop 中存储数据,这意味着我们所有的数据都存储在 HDFS 中。 Hadoop 还以其高效可靠的存储技术而闻名。那么您有没有想过 Hadoop 如何使其存储如此高效和可靠?是的,这里介绍了什么文件块的概念。复制因子不过是一个复制或重复数据的过程,因此让我们通过示例一一讨论它们以便更好地理解。
Hadoop 中的文件块
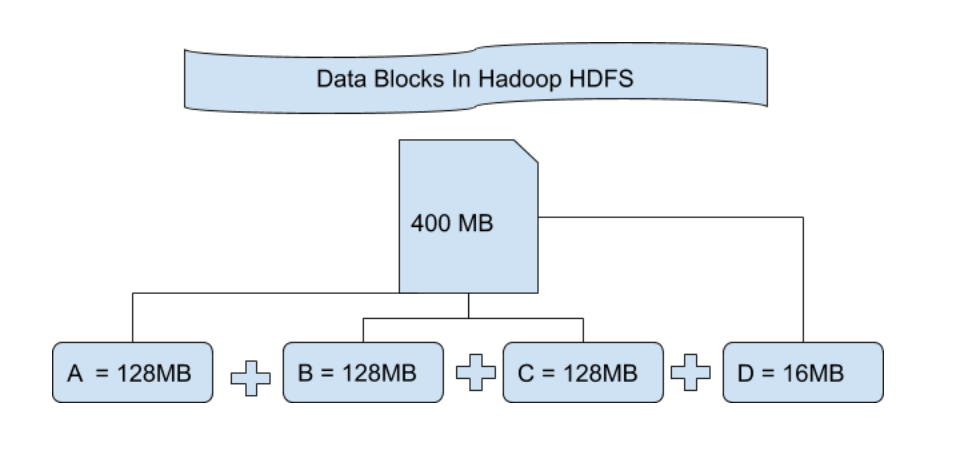
每当您将任何文件导入 Hadoop 分布式文件系统时,都会发生这种情况,该文件被分成一定大小的块,然后这些数据块存储在各个从属节点中。这是几乎所有类型的文件系统都会发生的一种正常现象。默认情况下,在 Hadoop1 中,这些块的大小为 64MB,而在 Hadoop2 中,这些块的大小为 128MB,这意味着分割文件后获得的所有块的大小应为 64MB 或 128MB。您可以手动更改hdfs-site.xml文件中文件块的大小。

让我们通过一个例子来理解这个以块为单位分解文件的概念。假设你已经上传了一个 400MB 的文件到你的 HDFS,那么会发生什么,这个文件被分成了 128MB + 128MB + 128MB + 16MB = 400MB 大小的块。意味着创建了 4 个块,每个块都为 128MB,除了最后一个。
Hadoop 不知道或不关心这些块中存储了哪些数据,因此它将最终文件块视为部分记录。在 Linux 文件系统中,一个文件块的大小约为 4KB,远小于 Hadoop 文件系统中文件块的默认大小。众所周知,Hadoop 主要用于存储 PB 级的大数据,这也是 Hadoop 文件系统不同于其他文件系统的原因,因为它可以扩展,现在 Hadoop 中考虑了 128MB 到 256MB 的文件块。
现在让我们了解为什么这些块非常巨大。主要有2个原因,如下所述:
- Hadoop 文件块更大,因为如果文件块的大小较小,那么在这种情况下,我们的 Hadoop 文件系统(即 HDFS)中将会有很多块。在这些小文件块中大量存储大量元数据会变得混乱,从而导致网络流量。
- 块变得更大,以便我们可以最大限度地减少寻找或查找的成本。因为有时从磁盘传输数据所花费的时间可能超过启动这些块所花费的时间。
文件块的优点:
- 易于维护,因为它的大小可能比我们集群中存在的任何单个磁盘都大。
- 我们不需要像任何权限一样处理元数据,因为它们可以在不同的系统上处理。因此无需将此元数据与文件块一起存储。
- 复制这些数据非常容易,这为我们的 Hadoop 集群提供了容错性和高可用性。
- 由于块具有固定的配置大小,我们可以轻松维护其记录。
复制和复制因子
复制可确保数据的可用性。复制只不过是复制某物,复制该特定事物的次数可以表示为它的复制因子。正如我们在文件块中看到的那样,HDFS 以各种块的形式存储数据,同时 Hadoop 也被配置为制作这些文件块的副本。默认情况下,Hadoop 的复制因子设置为 3,可以配置这意味着您可以根据您的要求手动更改它,就像在上面的示例中一样,我们制作了 4 个文件块,这意味着制作了每个文件块的 3 个副本或副本意味着总共4×3 = 12 个块用于备份目的。
现在你可能会怀疑为什么我们需要对我们的文件块进行这种复制,这是因为为了运行 Hadoop,我们使用的是随时可能崩溃的商品硬件(廉价的系统硬件)。我们没有使用超级计算机进行 Hadoop 设置。这就是为什么我们在 HDFS 中需要这样一个功能,它可以为备份目的制作该文件块的副本,这被称为容错。
现在我们还需要注意一件事,在制作了如此多的文件块副本之后,我们浪费了太多的存储空间,但对于大品牌组织而言,数据比存储空间重要得多。所以没有人关心这个额外的存储空间。
您可以在hdfs-site.xml文件中配置复制因子。
在这里,我们将复制因子设置为 1,因为我们只有一个系统可以使用 Hadoop,即一台笔记本电脑,因为我们没有任何具有大量节点的集群。您只需根据需要更改dfs.replication属性中的值。

复制如何工作?
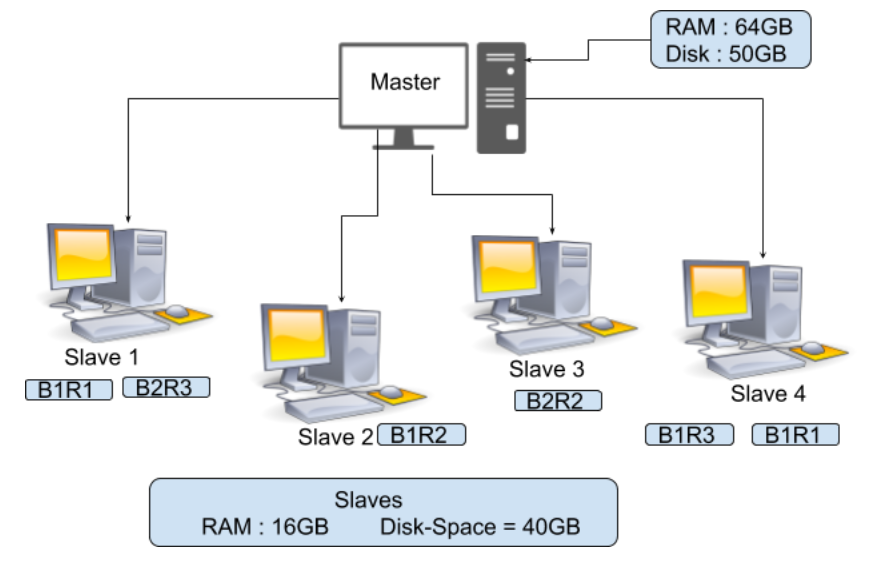
在上图中,您可以看到有一个 RAM = 64GB 和磁盘空间 = 50GB 的 Master 和 4 个 RAM = 16GB 和磁盘空间 = 40GB 的 Slave。在这里你可以观察到Master的RAM更多。它需要保留更多,因为你的主人是要引导这个奴隶的人,所以你的主人必须快速处理。现在假设您有一个大小为 150MB 的文件,那么总文件块将为 2,如下所示。
128MB = Block 1
22MB = Block 2由于默认的复制因子是 3,所以我们有这个文件块的 3 个副本
FileBlock1-Replica1(B1R1) FileBlock2-Replica1(B2R1)
FileBlock1-Replica2(B1R2) FileBlock2-Replica2(B2R2)
FileBlock1-Replica3(B1R3) FileBlock2-Replica3(B2R3)这些块将存储在我们的 Slave 中,如上图所示,这意味着如果您的 Slave 1 崩溃了,那么在这种情况下 B1R1 和 B2R3 会丢失。但是您可以从其他从站恢复 B1 和 B2,因为该文件块的副本已经存在于其他从站中,类似地,如果任何其他从站崩溃,那么我们可以从其他从站获取该文件块。复制将增加我们的存储,但数据对我们来说更必要。