Facebook、Instagram、亚马逊、Flipkart ……这些应用程序是很多人最喜欢的应用程序,而且很可能这些是您列表中经常访问的网站。
您是否注意到这些网站的加载时间比全新网站少?你有没有注意到,当你浏览一个网站时,在互联网连接速度较慢的情况下,文本会在任何高质量图像之前加载?
为什么会发生这种情况?答案是缓存。

如果您在互联网连接速度较慢的情况下检查 Instagram 页面,您会注意到图像不断加载,但文本会显示。对于任何类型的企业,这些事情都很重要。更好的客户/用户体验是最重要的事情,由于您网站的用户体验不佳,您可能会失去很多客户。如果用户发现当前网站加载或显示结果需要更多时间,他们会立即切换到另一个网站。您可以以在任何视频流应用程序上观看您喜爱的连续剧为例。如果视频一直在缓冲,你会有什么感觉?您不会坚持使用该服务并停止订阅的可能性更高。
上述所有问题都可以通过提高网站的保留率和参与度以及提供最佳用户体验来解决。最好的解决方案之一是缓存。
缓存 – 简介
假设您每天准备晚餐,并且您需要一些食材来准备食物。每当你准备食物时,你会去离你最近的商店购买这些食材吗?绝对没有。这是一个耗时的过程,每次您都不想去最近的商店,而是想购买一次食材,然后将其存放在冰箱中。这样会节省很多时间。这是缓存,您的冰箱就像缓存/本地商店/临时商店一样工作。如果冰箱中已有食物,则烹饪时间会缩短。
同样的事情发生在系统中。在系统中,从主内存 (RAM) 访问数据比从辅助内存(磁盘)访问数据要快。缓存充当数据的本地存储,从本地或临时存储中检索数据比从数据库中检索数据更容易、更快。将其视为短期记忆 有有限的空间,但速度更快,包含最近访问的项目。因此,如果您需要经常依赖某个数据,那么缓存数据并从内存而不是磁盘中更快地检索它。
注意:您知道缓存的好处,但这并不意味着您将所有信息都存储在缓存中以加快访问速度。出于多种原因,您不能这样做。原因之一是缓存的硬件比普通数据库贵得多。此外,如果您在缓存中存储大量数据,搜索时间也会增加。所以简而言之,缓存需要根据未来将要到来的请求拥有最相关的信息。
哪里可以添加缓存?
缓存几乎用于计算的每一层。例如,在硬件中,您有不同的高速缓存层。您有第 1 层缓存,即 CPU 缓存,然后是第 2 层缓存,最后是常规 RAM(随机存取存储器)。您还可以在操作系统中进行缓存,例如缓存各种内核扩展或应用程序文件。您还可以在 Web 浏览器中缓存以减少网站的加载时间。所以缓存几乎可以用在每一层:硬件、操作系统、Web 浏览器、Web 应用程序,但通常最靠近前端。
缓存如何工作?
通常,Web 应用程序将数据存储在数据库中。当客户端请求一些数据时,它会从数据库中获取,然后返回给用户。从数据库中读取数据需要网络调用和 I/O 操作,这是一个耗时的过程。缓存减少了对数据库的网络调用,并加快了系统的性能。以 Twitter 为例:当一条推文病毒式传播时,大量客户请求同一条推文。 Twitter是一个拥有数百万用户的巨大网站。对于如此大量的用户请求,从磁盘读取数据是低效的。减少 对数据库的调用次数,我们可以使用缓存,并且可以更快地提供推文。
在典型的 Web 应用程序中,我们可以在我们的应用程序服务器旁边添加一个应用程序服务器缓存,一个像 Redis 一样的内存存储。当第一次发出请求时,必须调用数据库来处理查询。这称为缓存未命中。在将结果返回给用户之前,结果将保存在缓存中。当用户第二次发出相同的请求时,应用程序将首先检查您的缓存以查看该请求的结果是否已缓存。如果是,则结果将从内存存储中返回。这称为缓存命中。第二次请求的响应时间会比第一次少很多。
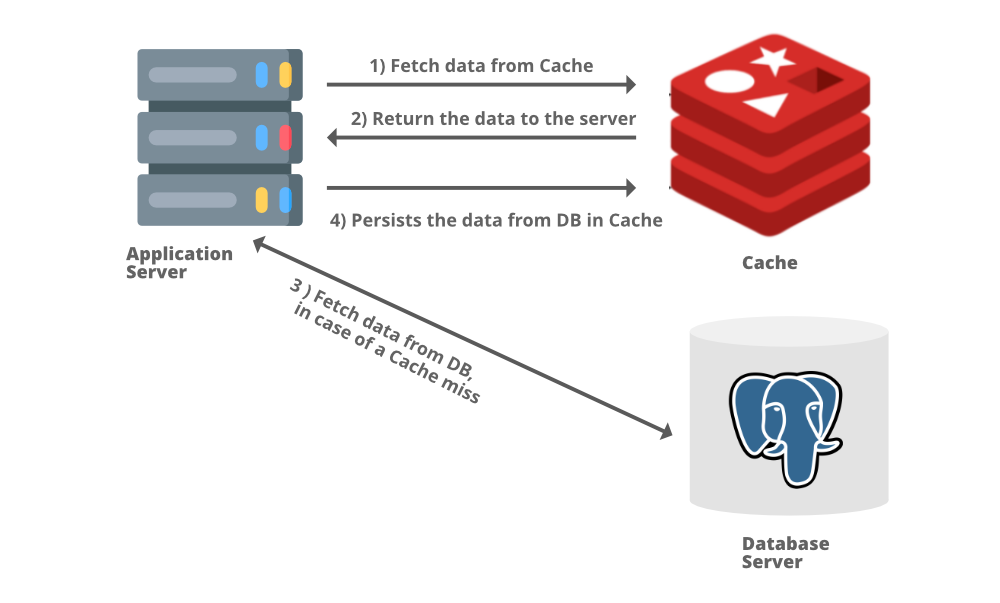
缓存类型
通常有四种类型的缓存……
1. 应用服务器缓存
在“缓存如何工作? ”部分我们讨论了如何在 Web 应用程序中添加应用服务器缓存。在 Web 应用程序中,假设 Web 服务器有一个节点。缓存可以与应用程序服务器一起添加到内存中。用户的请求将存储在此缓存中,并且每当相同的请求再次出现时,它将从缓存中返回。对于新的请求,将从磁盘中获取数据,然后将其返回。一旦新的请求从磁盘返回,它就会存储在同一个缓存中,以供用户下次请求使用。在请求层节点上放置缓存可启用本地存储。
注意:当您将缓存放在内存中时,服务器中的内存量将被缓存用完。如果您正在处理的结果数量非常少,那么您可以将缓存保留在内存中。
当您需要扩展系统时就会出现问题。您在 Web 应用程序中添加了多个服务器(因为一个节点无法处理大量请求)并且您有一个负载均衡器可以将请求发送到任何节点。在这种情况下,您最终会遇到很多缓存未命中,因为每个节点都不会知道已经缓存的请求。这不是很好,为了克服这个问题,我们有两种选择:分布式缓存和全局缓存。让我们讨论一下……
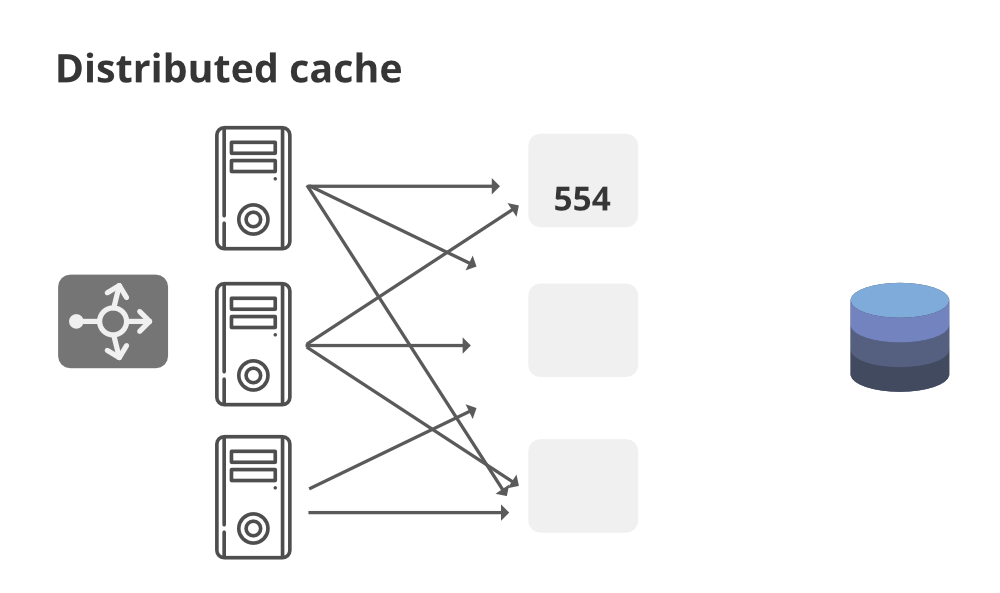
2. 分布式缓存
在分布式缓存中,每个节点都会拥有整个缓存空间的一部分,然后使用一致性哈希函数每个请求路由到可以找到缓存请求的地方。假设我们在分布式系统中有 10 个节点,并且我们正在使用负载均衡器来路由请求,然后……
- 它的每个节点都将拥有一小部分缓存数据。
- 为了识别哪个节点具有哪个请求,使用一致的散列函数划分缓存,可以将每个请求路由到可以找到缓存请求的位置。如果请求节点正在寻找某条数据,它可以快速知道在分布式缓存中查找的位置以检查数据是否可用。
- 我们可以通过简单地将新节点添加到请求池中来轻松增加缓存内存。
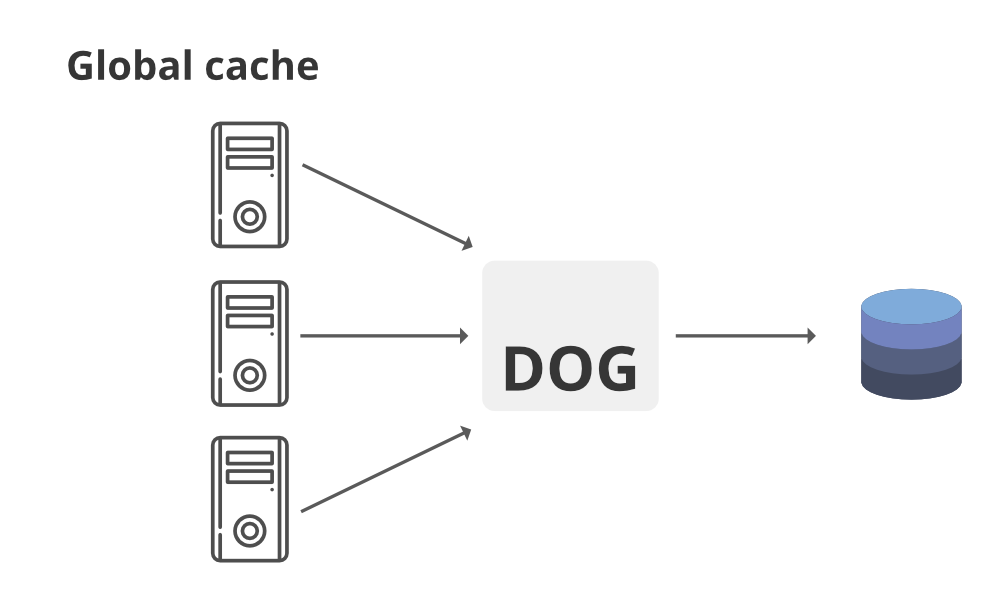
3. 全局缓存
顾名思义,您将拥有一个缓存空间,所有节点都使用这个空间。每个请求都会进入这个单一的缓存空间。有两种全局缓存
- 首先,当在全局缓存中找不到缓存请求时,缓存有责任从存储底层的任何地方(数据库、磁盘等)找出丢失的数据。
- 其次,如果请求来了并且缓存没有找到数据,那么请求节点将直接与数据库或服务器通信以获取请求的数据。
4. CDN(内容分发网络)
CDN 用于网站提供大量静态内容的情况。这可以是 HTML 文件、CSS 文件、JavaScript 文件、图片、视频等。首先向 CDN 请求数据,如果存在则返回数据。如果没有,CDN 将查询后端服务器,然后将其缓存在本地。
缓存失效
缓存很棒,但是数据库中不断更新的数据呢?如果在 DB 中修改了数据,则应将其失效以避免不一致的应用程序行为。那么如何使缓存中的数据与数据库中真实来源的数据保持一致呢?为此,我们需要使用一些缓存失效方法。存在三种不同的缓存失效方案。让我们一一讨论……
1. 直写缓存
顾名思义,数据首先写入缓存,然后写入数据库。通过这种方式,您可以保持数据库和缓存之间数据的一致性。在缓存上完成的每次读取都遵循最近的写入。
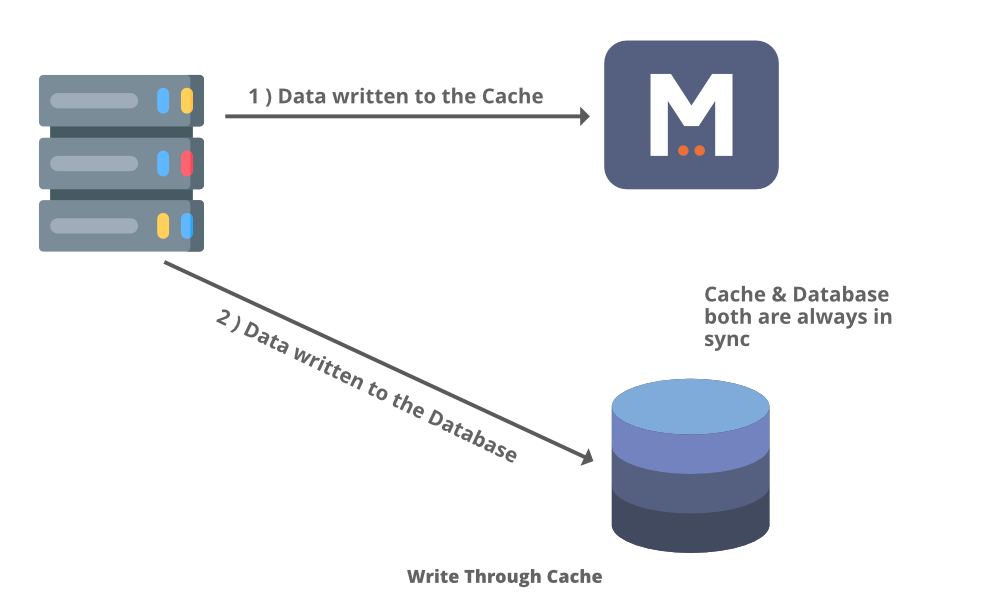
这种方法的优点是可以最大限度地降低数据丢失的风险,因为它同时写入缓存和数据库中。但是这种方法的缺点是写入操作的延迟较高,因为您需要在两个地方为单个更新请求写入数据。如果您没有大量数据,那很好,但是如果您有大量写入操作,那么这种方法不适合这些情况。
我们可以将这种方法用于一旦数据持久化到数据库中就会频繁重新读取数据的应用程序。在这些应用程序中,写入延迟可以通过较低的读取延迟和一致性来补偿。
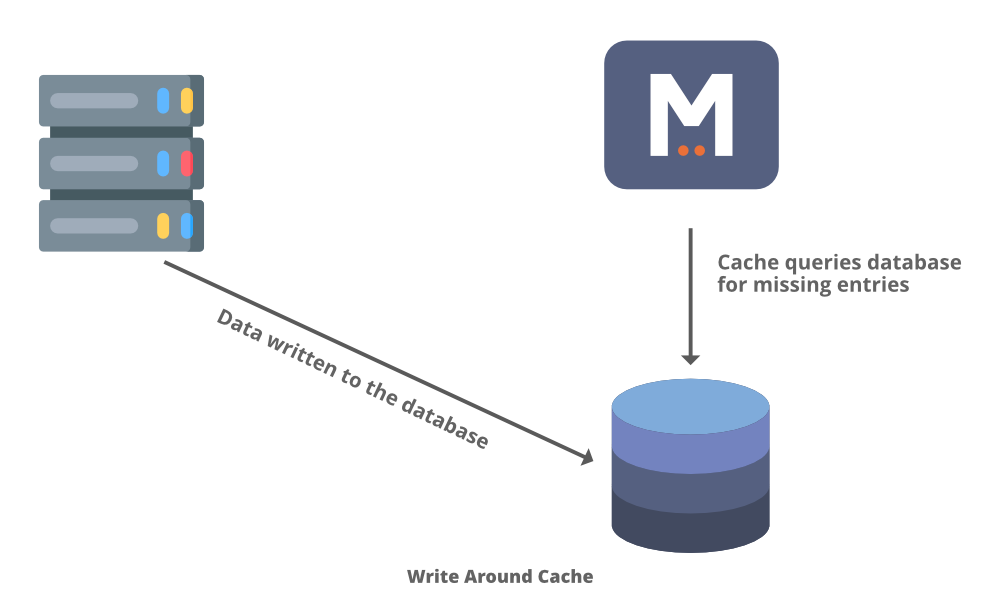
2.写缓存
类似于写透你 写入数据库,但在这种情况下,您不更新缓存。所以数据直接写入存储,绕过缓存。您不需要使用不会重新读取的数据加载缓存。与直写缓存相比,这种方法减少了泛滥的写操作。这种方法的缺点是对最近写入的数据的读取请求会导致缓存未命中,并且必须从较慢的后端读取。因此这种方法适用于不经常重新读取最新数据的应用程序。
3.写回缓存
我们已经讨论过,由于延迟较高,直写缓存不适合写入密集型系统。对于这些类型的系统,我们可以使用回写缓存方法。首先从缓存中刷新数据,然后单独将数据写入缓存。一旦缓存中的数据更新,将数据标记为已修改,这意味着稍后需要在DB中更新数据。稍后将执行异步作业,并定期从缓存中读取修改后的数据,以使用相应的值更新数据库。
这种方法的问题在于,在您安排更新数据库之前,系统存在数据丢失的风险。假设您更新了缓存中的数据,但出现磁盘故障并且修改后的数据尚未更新到数据库中。由于数据库是事实的来源,如果您从数据库中读取数据,您将无法获得准确的结果。
驱逐政策
我们已经讨论了很多缓存的概念……现在你可能有一个问题在你的脑海中。我们什么时候需要做出/加载进入缓存和数据,我们需要从缓存中删除?
您系统中的缓存可能在任何时候都已满。所以,我们需要使用一些算法或策略将数据从缓存中移除,并且我们需要加载其他更有可能在未来被访问的数据。为了做出这个决定,我们可以使用一些缓存驱逐策略。让我们一一讨论一些缓存驱逐策略……
1. LRU(最近最少使用)
LRU 是最流行的策略 由于几个原因。它很简单,具有良好的运行时性能,并且在常见工作负载中具有不错的命中率。顾名思义,此策略首先从缓存中驱逐最近最少使用的项目。当缓存变满时,它会删除最近最少使用的数据,并将最新的条目添加到缓存中。
每当您需要将条目添加到缓存时,请将其保留在顶部,并从缓存中删除最近最少使用的最底部条目。最重要的条目可能是几秒钟前,然后您在几分钟前、几小时前、几年前继续向下列表,然后删除最后一个条目(最近最少使用)。
考虑任何社交媒体网站的示例,有一位名人发表了帖子或发表了评论,每个人都想提取该评论。因此,您将该帖子保留在缓存的顶部,它会根据帖子的最新情况保留在缓存的顶部。当帖子变冷或人们停止查看或查看该帖子时,它会一直推送到缓存的末尾,然后从缓存中完全删除。
我们可以使用双向链表和包含链表中节点引用的哈希函数来实现 LRU。
2. LFU(最不常用)
此策略计算每个请求项的频率,并从缓存中丢弃最不频繁的项。所以在这里我们计算一个数据项被访问的次数,并跟踪每个项目的频率。当缓存大小达到给定阈值时,我们删除频率最低的条目。
在现实生活中,我们可以以在手机上输入一些文本为例。当您在文本框中键入内容时,您的手机会建议多个字词。您可以选择从这些多个单词中选择一个单词,而不是输入整个单词。在这种情况下,您的手机会跟踪您键入的每个单词的频率并为其维护缓存。稍后在需要时将频率最低的单词从缓存中丢弃。如果我们发现多个单词之间存在联系,则删除最近最少使用的单词。
3. MRU(最近使用)
这种方法从缓存中删除最近使用的项目。我们优先考虑保留在缓存中的旧项目。这种方法适用于用户对查看最新数据或项目不太感兴趣的情况。现在您可能会想,大多数情况下用户对最新的数据或条目感兴趣,所以可以在哪里使用它?好吧,您可以以可以使用 MRU 的约会应用程序 Tinder 为例。
Tinder 维护用户所有潜在匹配项的缓存。当用户在应用程序中向左/向右滑动配置文件时,它不会向用户推荐相同的配置文件。如果一次又一次地推荐相同的配置文件,将会导致糟糕的用户体验。因此,tinder 从缓存中删除了最近观察到的配置文件,即向左/向右滑动的配置文件。
4.随机更换
顾名思义,我们随机选择一个项目并将其从缓存中丢弃以在必要时腾出空间。