设计一个 URL 缩短服务是系统设计轮面试中经常被问到的常见问题之一。您必须在有限的时间范围内( 45 分钟或更短)说明您设计此服务的方法。许多候选人更害怕这一轮而不是编码轮,因为他们不知道在有限的时间内应该涵盖哪些主题和权衡。首先,请记住,系统设计回合是非常开放的,没有标准答案之类的东西。即使是同样的问题,不同的面试官也会有完全不同的讨论。

在这个博客中,我们将讨论如何设计一个 URL 缩短服务,但在我们进一步讨论之前,我们希望您阅读文章“如何在面试中破解系统设计回合?”。它会让你知道这一轮是什么样子,你在这一轮中应该做什么,以及在面试官面前应该避免哪些错误。
你会如何设计像 TinyURL 这样的 URL Shortener 服务?
像 bit.ly 或 TinyURL 这样的 URL 缩短服务非常受欢迎,可以为长 URL 生成较短的别名。您需要设计这种 Web 服务,如果用户提供长 URL,则服务返回短 URL,如果用户提供短 URL,则返回原始长 URL。例如,通过 TinyURL 缩短给定的 URL:
https://www.geeksforgeeks.org/get-your-dream-job-with-amazon-sde-test-series/?ref=leftbar-rightbar我们得到下面给出的结果
https://tinyurl.com/y7vg2xjl很多候选人可能会认为设计这项服务并不困难。当用户给出长 URL 时,将其转换为短 URL 并更新数据库,当用户点击短 URL 时,然后在数据库中搜索短 URL,获取该长 URL,并将用户重定向到原始 URL。真的很简单吗?如果我们考虑此服务的可扩展性,绝对不会。
当你在面试中被问到这个问题时,不要立即进入技术细节。大多数候选人在这里犯了错误,然后他们立即开始列出一些工具、数据库和框架。在这类问题中,面试官想要一个高层次的设计理念,您可以在其中给出服务的可扩展性和持久性的解决方案。
我们先从需求说起……
一、要求
在你跳入解决方案之前,总是澄清你在面试开始时所做的所有假设。提出问题以确定系统的范围。这将消除最初的疑问,您将了解面试官在此服务中想要考虑的具体细节。
- 给定一个长 URL,服务应该为其生成一个更短且唯一的别名。
- 当用户点击一个短链接时,服务应该重定向到原始链接。
- 链接将在标准默认时间跨度后过期。
- 系统应该是高可用的。考虑这一点非常重要,因为如果服务出现故障,所有 URL 重定向都将开始失败。
- URL 重定向应该以最小的延迟实时发生。
- 缩短的链接不应该是可预测的。
让我们首先对流量(为了可扩展性)和 URL 的长度做一些假设。
2. 交通
假设我们的服务每月有 3000 万个新的 URL 缩短。假设我们将每个 URL 缩短请求(以及相关的缩短链接)存储 5 年。在此期间,该服务将生成大约 1.8 个 B 记录。
30 million * 5 years * 12 months = 1.8B3. 网址长度
假设我们使用 7 个字符来生成一个短 URL。这些字符是 62 个字符[AZ, az, 0-9] 的组合,例如http://ad.com/abXdef2 。
4. 数据容量建模
讨论数据容量模型以估计系统的存储量。我们需要了解可能需要在系统中插入多少数据。考虑将存储在我们数据库中的不同列或属性,并计算数据存储五年。让我们对不同的属性做出下面给出的假设……
- 考虑 2KB 的平均长 URL 大小,即 2048 个字符。
- 短 URL 大小:17 个字节为 17 个字符
- created_at- 7 字节
- expire_length_in_minutes -7 字节
上述计算将在数据库中为每个缩短的 URL 条目提供总共 2.031KB。如果我们计算总存储量,那么对于 30 M 活跃用户,总大小 = 30000000 * 2.031 = 60780000 KB = 60.78 GB 每月。一年 0.7284 TB,5 年后 3.642 TB 数据。
我们需要考虑将在我们的系统上针对此数量的数据进行的读取和写入。这将决定我们需要使用哪种数据库(RDBMS 或 NoSQL)。
5. URL 缩短逻辑(编码)
要将长 URL 转换为唯一的短 URL,我们可以使用一些散列技术,如 Base62 或 MD5。我们将讨论这两种方法。
Base62 编码: Base62 编码器允许我们使用包含 AZ、az、0-9 的字符和数字的组合(26 + 26 + 10 = 62)。因此,对于 7 个字符的短 URL,我们可以提供 62^7 ~= 35000 亿个 URL,这与 base10 相比已经足够了(base10 仅包含数字 0-9,因此您只能获得 10M 组合)。如果我们使用 base62 假设服务每秒生成 1000 个微小的 URL,那么耗尽这 35000 亿个组合将需要 110 年的时间。我们可以为给定的长 URL 生成一个随机数并将其转换为 base62 并将哈希用作短 URL id。
Python3
def to_base_62(deci):
s = '012345689abcdefghijklmnopqrstuvwxyzABCDEFGHIJKLMNOPQRSTUVWXYZ'
hash_str = ''
while deci > 0:
hash_str= s[deci % 62] + hash_str
deci /= 62
return hash_str
print to_base_62(999)MD5 编码: MD5 还提供 base62 输出,但 MD5 散列给出了超过 7 个字符的冗长输出。 MD5 哈希生成 128 位长输出,因此在 128 位中,我们将使用 43 位来生成 7 个字符的小 URL。 MD5 会产生很多冲突。对于两个或多个不同的长 URL 输入,我们可能会为短 URL 获得相同的唯一 ID,这可能会导致数据损坏。因此,我们需要执行一些检查以确保数据库中不存在此唯一 ID。
6. 数据库
我们可以使用使用 ACID 属性的 RDBMS,但您将面临关系数据库的可扩展性问题。现在,如果您认为可以使用分片并解决 RDBMS 中的可扩展性问题,那么这将增加系统的复杂性。有 3000 万活跃用户,因此会有转换和大量短 URL 解析和重定向。对于这 3000 万用户而言,读取和写入将很繁重,因此当我们希望以分布式方式拥有系统时,使用分片扩展 RDBMS 将增加设计的复杂性。在 RDBMS 的情况下,您可能必须使用一致的哈希来平衡流量和数据库查询,这是一个复杂的过程。因此,在我们的系统关系数据库上处理如此大量的流量是不合适的,而且扩展 RDBMS 也不是一个好的决定。
现在让我们来谈谈 NoSQL!
使用 NoSQL 数据库的唯一问题是它的最终一致性。我们写了一些东西,复制到不同的节点需要一些时间,但我们的系统需要高可用性,而 NoSQL 符合这个要求。 NoSQL 可以轻松处理 30M 的活跃用户,并且易于扩展。当我们想要扩展存储时,我们只需要不断添加节点。
生成和存储 TinyURL 的技术
技巧一
让我们讨论在我们的数据库中将长 URL 映射到短 URL。假设我们使用 base62 编码生成 Tiny URL,那么我们需要执行以下步骤……
- 这个微小的 URL 应该是唯一的,所以首先检查数据库中这个微小的 URL 是否存在(在 DB 上执行 get(tiny))。如果它已经存在于其他一些长 URL 中,则生成一个新的短 URL。
- 如果 DB 中不存在短 URL,则将 longURL 和 TinyURL 放入 DB (put(TinyURL, longURL))。
这种技术在一台服务器上工作得很好,但如果有多个服务器,那么这种技术会产生竞争条件。当多台服务器一起工作时,有可能它们都可以为不同的长 URL 生成相同的唯一 id 或相同的小 URL,甚至在检查数据库后,它们也将被允许同时插入相同的小 URL(即对于数据库中不同的长 URL 是相同的),这最终可能会损坏数据。
我们可以在插入小 URL 时使用 putIfAbsent(TinyURL, long URL) 或 INSERT-IF-NOT-EXIST 条件,但这需要 DB 的支持,这在 RDBMS 中可用但在 NoSQL 中不可用。数据在 NoSQL 中最终是一致的,因此在 NoSQL 数据库中可能不支持 putIfAbsent 功能。
技术 2(MD5 方法)
- 使用 MD5 方法对长 URL 进行编码,并仅使用前 7 个字符来生成 TinyURL。
- 对于不同的长 URL,前 7 个字符可能相同,因此请检查数据库(如我们在技术 1 中讨论的那样)以验证 TinyURL 尚未使用
- 优点:这种方式在数据库中节省了一些空间,但是如何呢?如果两个用户想为同一个长 URL 生成一个小 URL,那么第一种技术将生成两个随机数,它需要数据库中的两行,但在第二种技术中,两个较长的 URL 将具有相同的 MD5,因此它将具有相同的前 43 位,这意味着我们将进行一些重复数据删除,我们最终将节省一些空间,因为我们只需要在数据库中存储一行而不是两行。
MD5 为相同的 URL 在数据库中节省了一些空间,但是对于两个不同的长 URL,我们将再次面临与技术 1 中讨论的相同的问题。我们可以使用 putIfAbsent 但 NoSQL 不支持此功能。所以让我们转向第三种技术来解决这个问题。
技巧三(反方法)
对于可扩展的解决方案,使用计数器是一个很好的决定,因为计数器总是会递增,因此我们可以为每个新请求获取一个新值。
单服务器方法:
- 单个主机或服务器(比如数据库)将负责维护计数器。
- 当工作主机收到请求时,它会与计数器主机对话,计数器主机会返回一个唯一的数字并递增计数器。当下一个请求到来时,计数器主机再次返回唯一编号,然后继续。
- 每个工作主机都有一个唯一的编号,用于生成 TinyURL。
问题:如果计数器主机停机一段时间,则会产生问题,如果请求数量很高,则计数器主机可能无法处理负载。所以挑战是单点故障和单点瓶颈。
如果有多个服务器怎么办?
您无法维护一个计数器并将输出返回给所有服务器。为了解决这个问题,我们可以为使用不同计数器范围的多个服务器使用多个内部计数器。例如服务器 1 的范围从 1 到 1M,服务器 2 的范围从 1M 到 10M,依此类推。但是我们将再次面临一个问题,即如果其中一个计数器出现故障,那么对于另一台服务器,将很难获得故障计数器的范围并再次维护它。此外,如果一个计数器达到其最大限制,则重置计数器将很困难,因为没有单个主机可用于所有这些多台服务器之间的协调。由于我们不知道哪个服务器是主服务器,哪个是从服务器,哪个负责协调和同步,所以架构会一团糟。
解决方案:为了解决这个问题,我们可以使用分布式服务 Zookeeper 来管理所有这些繁琐的任务,并解决分布式系统的各种挑战,如竞争条件、死锁或数据粒子故障。 Zookeeper 基本上是一个管理大量主机的分布式协调服务。它跟踪所有事情,例如服务器的命名、活动服务器、死服务器、所有主机的配置信息。它提供协调并维护多个服务器之间的同步。
让我们讨论如何使用 Zookeeper 为分布式主机维护一个计数器。
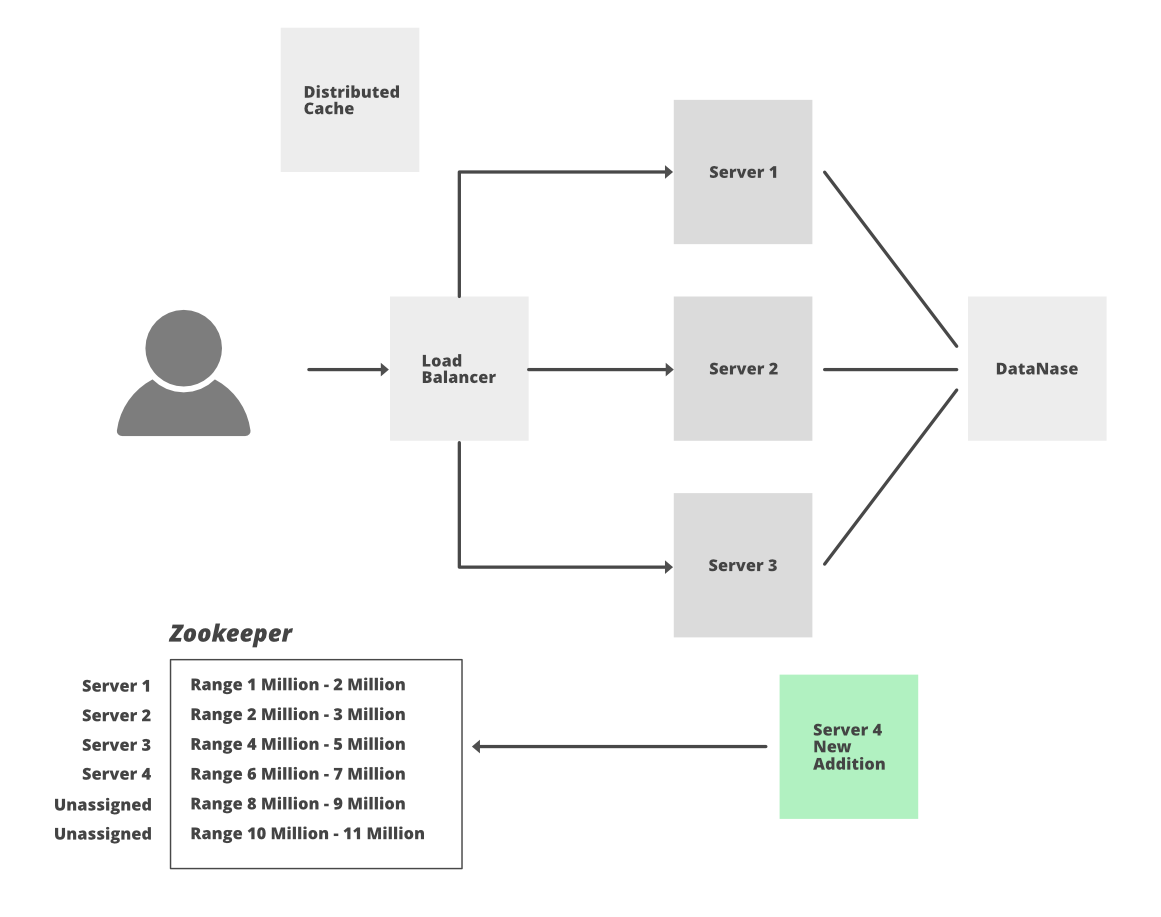
- 从 3.5 万亿个组合中取第 1 个十亿个组合。
- 在 Zookeeper 中维护范围并将第 10 亿划分为 1000 个范围,每个范围为 100 万个,即范围 1->(1 – 1,000,000),范围 2->(1,000,001 – 2,000,000)…。范围 1000->(999,000,001 – 1,000,000,000)
- 添加服务器时,这些服务器将向 Zookeeper 请求未使用的范围。假设 W1 服务器被分配了范围 1,现在 W1 将生成微小的 URL,增加计数器并使用编码技术。每次它将是一个唯一的数字,因此没有冲突的可能性,也没有必要继续检查数据库以确保 URL 是否已经存在。我们可以直接将长 URL 和短 URL 的映射插入到 DB 中。
- 在最坏的情况下,如果其中一台服务器宕机,那么我们只会在 Zookeeper 中丢失一百万个组合(这将是未使用的,我们也不能重用它),但由于我们有 3.5 万亿个组合,我们不应该担心丢失这个组合。
- 如果其中一台服务器将达到其最大范围或限制,则它可以再次从 Zookeeper 获取新的范围。
- 添加新服务器也很容易。 Zookeeper 将为这个新服务器分配一个未使用的计数器范围。
- 当第一个十亿用完时,我们将拿第二个十亿继续这个过程。