错误处理过程的任务是检测每个错误,将其报告给用户,然后制定一些恢复策略并实施它们来处理错误。在这整个过程中,程序的处理时间应该不会很慢。
错误处理程序的功能:
- 错误检测
- 错误报告
- 错误恢复
Error handler=Error Detection+Error Report+Error Recovery.错误是符号表中的空白条目。
解析器应该检测并报告程序中的错误。每当发生错误时,解析器可以处理它并继续解析输入的其余部分。尽管解析器主要负责检查错误,但在编译过程的各个阶段都可能发生错误。
因此,有许多类型的错误,其中一些是:
错误的类型或来源 –有三种类型的错误:逻辑错误、运行时错误和编译时错误:
- 当程序运行不正确但没有异常终止(或崩溃)时,就会发生逻辑错误。意外或不希望的输出或其他行为可能由逻辑错误导致,即使它没有立即被识别出来。
- 运行时错误是在程序执行过程中发生的错误,通常是由于不利的系统参数或无效的输入数据而发生的。缺乏足够的内存来运行应用程序或与另一个程序的内存冲突和逻辑错误就是一个例子。当执行的代码没有产生预期的结果时,就会发生逻辑错误。逻辑错误最好通过细致的程序调试来处理。
- 编译时错误在编译时出现,在程序执行之前。阻止程序成功编译的语法错误或缺少文件引用就是一个例子。
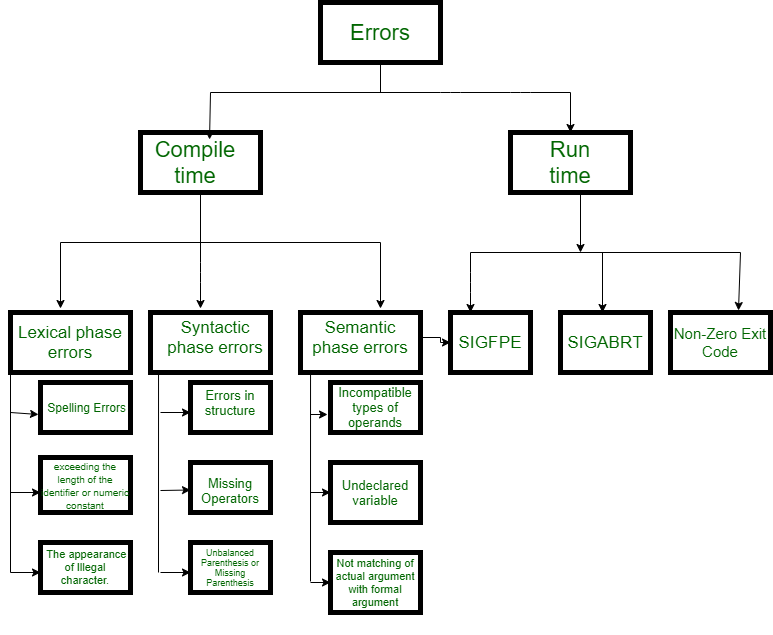
编译时错误的分类 –
- 词法:这包括标识符、关键字或运算符的拼写错误
- 语法:缺少分号或不平衡的括号
- 语义:不兼容的赋值或运算符和操作数之间的类型不匹配
- 逻辑:代码不可访问,无限循环。
发现错误或报告错误——可行前缀是解析器的属性,它允许及早检测语法错误。
- 在不进一步消耗不必要的输入的情况下尽快检测错误的目标
- 如何:只要输入的前缀与语言中任何字符串的前缀不匹配,就会检测到错误。
例如: for( ; ),这将报告错误,因为大括号内有两个分号。
错误恢复——
编译器的基本要求是简单地停止并发出消息,然后停止编译。有一些常见的恢复方法如下。
我们已经讨论了错误。现在,让我们尝试了解编译器每个阶段的错误恢复。
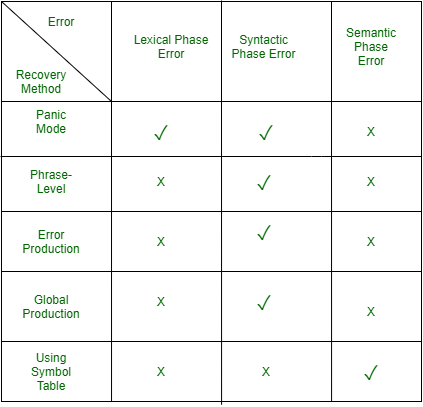
1. 恐慌模式恢复:
这是错误恢复的最简单方法,而且它可以防止解析器在恢复错误时开发无限循环。解析器一次丢弃一个输入符号,直到找到一组指定的(如结束、分号)同步标记(通常是语句或表达式终止符)。当同一语句中很少出现多个错误时,这就足够了。示例:考虑错误的表达式- (1 + + 2) + 3。恐慌模式恢复:向前跳到下一个整数,然后继续。 Bison:使用特殊的终端错误来描述要跳过多少输入。
E->int|E+E|(E)|error int|(error) 2. 相位恢复:
当发现错误时,解析器对剩余的输入执行本地更正。如果解析器遇到错误,它会对剩余的输入进行必要的更正,以便解析器可以继续解析语句的其余部分。您可以通过删除多余的分号、用分号替换逗号或重新引入丢失的分号来纠正错误。为防止在校正过程中进入无限循环,应格外小心。每当在剩余的输入中找到任何前缀时,它就会被替换为一些字符串。这样,解析器就可以继续对其执行进行操作。
3.错误产生:
如果用户知道语法中遇到的常见错误以及产生错误结构的错误,则可以合并使用错误产生方法。使用时,在解析过程中会产生错误信息,可以继续解析。示例:写 5x 而不是 5*x
4.全局修正:
为了从错误输入中恢复,解析器分析整个程序并尝试为它找到最接近的匹配,这是无错误的。最接近的匹配是一种不会对标记进行多次插入、删除和更改的匹配。由于时间和空间复杂度高,这种方法并不实用。
下一篇相关文章 – 编译器中的错误检测和恢复