以下问题已在 GATE CS 2010 考试中提出。
1) 下面给出了火车预订数据库的关系模式。
乘客(pid、pname、年龄)
预订(pid、class、tid)
Table: Passenger
pid pname age
-----------------
0 Sachin 65
1 Rahul 66
2 Sourav 67
3 Anil 69
Table : Reservation
pid class tid
---------------
0 AC 8200
1 AC 8201
2 SC 8201
5 AC 8203
1 SC 8204
3 AC 8202
对于上述表的实例,以下 SQL 查询返回哪些 pid?
SLECT pid
FROM Reservation ,
WHERE class ‘AC’ AND
EXISTS (SELECT *
FROM Passenger
WHERE age > 65 AND
Passenger. pid = Reservation.pid)
(一) 1, 0
(二) 1、2
(三) 1、3
(S) 1, 5
答案 (C)
当子查询使用来自外部查询的值时,该子查询称为相关子查询。对于外部查询处理的每一行,相关子查询都会被评估一次。
外部查询从 Reservation 表中选择 4 个条目(pid 为 0、1、5、3)。在这些选定的条目中,子查询仅返回 1 和 3 的非空值。
2) 以下哪个并发控制协议既能保证冲突可串行化,又能避免死锁?
一、两相锁定
二、时间戳排序
(A) 我只
(B) 仅 II
(C) I 和 II
(D) 既不是 I 也不是 II
答案 (B)
2 Phase Locking (2PL) 是一种保证可串行化的并发控制方法。该协议利用事务对数据应用的锁,这可能会阻止(解释为停止信号)其他事务在事务生命周期中访问相同的数据。 2PL 可能会导致由于两个或多个事务相互阻塞而导致的死锁。看下面的情况,T3和T4都不能进步。 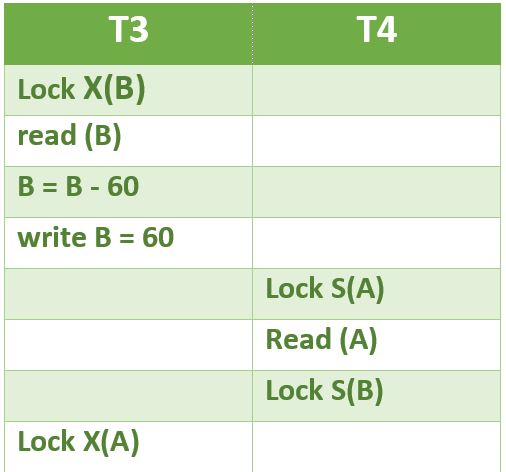
基于时间戳的并发控制算法是一种无锁的并发控制方法。在基于时间戳的方法中,不会发生死锁,因为没有事务等待。
3) 考虑以下事务 T1、T2 和 T3 的时间表: 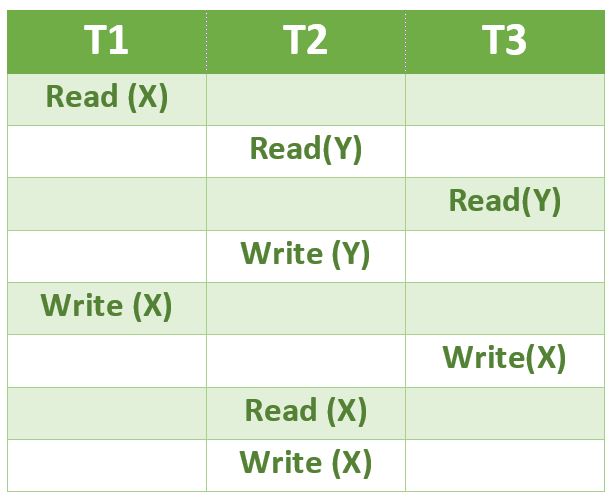
以下哪个时间表是上述时间表的正确序列化?
(A)T1 →T3 →T2
(B)T2 →T1 →T3
(C)T2 →T3 → T1
(D)T3 →T1 →T2
答案 (A)
T1 可以在 T2 和 T3 之前完成,因为在上图中 T1 的 Write(X) 与 T2 和 T3 中发生在 T1 的 Write(X) 之前的操作之间没有冲突。
T3 应该可以在 T2 之前完成,因为 T3 的 Read(Y) 与 T2 的 Read(Y) 不冲突。同样,T3 的 Write(X) 与 T2 的 Read(Y) 和 Write(Y) 操作不冲突。
解决这个问题的另一种方法是创建一个依赖图并对依赖图进行拓扑排序。拓扑排序后,我们可以看到序列T1,T3,T2。
4) 对于关系 R(A, B, C) 和 S(B, D, E),下列哪些函数依赖成立:
乙→甲,
A → C
关系 R 包含 200 个元组,关系 S 包含 100 个元组。是什么
自然连接中可能的最大元组数 R◊◊S(R 自然连接 S)
(一) 100
(乙) 200
(四) 300
(四) 2000
答案 (A)
从给定的一组函数依赖中,可以看出 B 是 R 的候选键。所以 B 的所有 200 个值在 R 中必须是唯一的。 S 没有给出函数依赖。要获得最大数量的元组输出,S 有两种可能。
1) S 中 B 的所有 100 个值都相同,并且 R 中存在与该值匹配的条目。在这种情况下,我们在输出中得到 100 个元组。
2) S 中 B 的所有 100 个值都不同,这些值也存在于 R 中。在这种情况下,我们也得到 100 个元组。
请参阅 GATE Corner 了解所有往年论文/解决方案/解释、教学大纲、重要日期、笔记等。