先决条件–自上而下的解析器分类
Predictive解析是递归下降解析的一种特殊形式,不需要回溯,因此可以预测使用哪个生产来替换输入字符串。
非递归预测分析或表驱动的也称为LL(1)解析器。该解析器遵循最左边的导数(LMD)。
LL(1):
here, first L is for Left to Right scanning of inputs,
the second L is for left most derivation procedure,
1 = Number of Look Ahead Symbols 预测解析过程中的主要问题是确定要应用于非终端的产品。
此非递归解析器查找要在解析表中应用的生产。 LL(1)解析器具有以下组件:
(1) buffer: an input buffer which contains the string to be passed
(2) stack: a pushdown stack which contains a sequence of grammar symbols
(3) A parsing table: a 2d array M[A, a]
where
A->non-terminal, a->terminal or $
(4) output stream:
end of the stack and an end of the input symbols are both denoted with $ 非递归预测解析算法:
主要概念->借助FIRST()和FOLLOW()设置,可以使用仅一个堆栈来进行此解析,从而避免了递归调用。
对于每个规则,语法G中的A-> x:
- 对于FIRST(A)中包含的每个终端“ a”,如果x派生“ a”作为第一个符号,则在解析表中向M [A,a]添加A-> x。
- 如果FIRST(A)在FOLLOW(A)中的每个终端’b’包含空产量,则在分析表中将此产量(A-> null)添加到M [A,b]。
程序,流程:
- 首先,下推堆栈保存语法G的开始符号。
- 在每一步中,符号X从堆栈中弹出:
如果X是终端,则将其与前行匹配并将前行前进一级,
如果X是一个非终止符,则使用前瞻和解析表(实现FIRST集),选择一个生产,并将其右侧压入堆栈。 - 重复此过程,直到堆栈和输入字符串变为空(空)为止。
表驱动的解析算法:
输入:一个字符串w和一个用于G的解析表M。
tos栈顶Stack [tos ++] <-$ Stack [tos ++] <-开始符号令牌<-next_token()X <-Stack [tos]如果X是终端或$,则重复,则X =令牌然后弹出X令牌是token()的下一个,否则eror()else / * X是一个非终结符* /如果M [x,令牌] = X-> y1y2 … yk,则弹出x推![]() 否则error()X Stack [tos]直到X = $
否则error()X Stack [tos]直到X = $
//非递归解析器模型图:
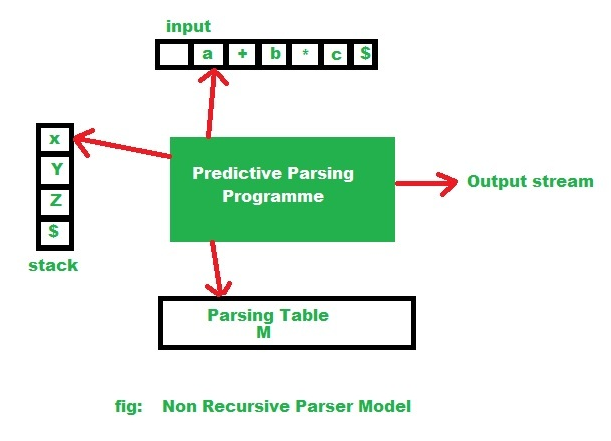
因此,根据给定的图,使用非递归解析算法。
输入:输入字符串’w’和语法G的解析表(’M’)。
输出:如果w在L(G)中,则LMD为w;如果w在L(G)中,则LMD为w。否则为错误指示。
将输入指针设置为指向字符串$的第一个符号。重复令X为堆栈指针指向的符号, a为输入指针指向的符号;如果X是一个终端或$,则如果X = a,则从堆栈中弹出X并增加输入指针;否则eror()结束,否则/ *如果X是一个非终结符* /如果![]() 然后从堆栈开始弹出X;推
然后从堆栈开始弹出X;推![]() 放在堆栈上,Y1在顶部;输出生产
放在堆栈上,Y1在顶部;输出生产![]() 否则,否则eror()如果结束则结束,直到X = $ / *堆栈为空* /
否则,否则eror()如果结束则结束,直到X = $ / *堆栈为空* /
示例:考虑随后的LL(1)语法:
S -> A
S -> ( S * A)
A -> id 现在让我们解析给定的输入:
( id * id ) 解析表:
- 对于每个非终结符,请使用row->
- 每个终端(包括特殊终端)的column->。
该表的每个单元格最多包含给定语法的一个规则:

现在,让我们看看使用算法,解析器如何使用此解析表来处理给定的输入。
程序:
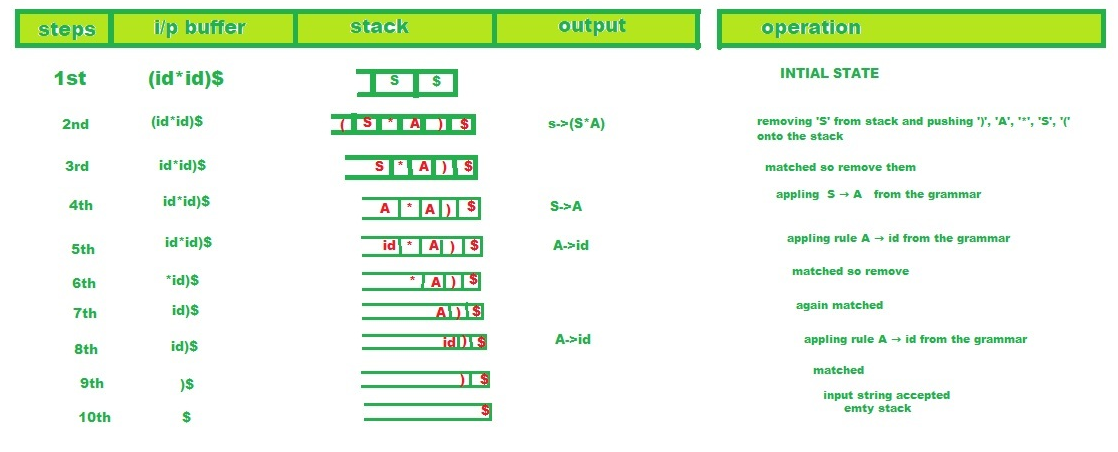
解析器因此结束,因为它的堆栈和输入流都只保留“ $”。在这种情况下,解析器报告它已接受输入字符串,并将以下规则列表写入输出流:
S -> ( S * A),
S -> A,
A -> id,
A -> id 这确实是输入字符串的LMD的规则列表,它是:
S -> ( S * A ) -> ( A * A ) -> ( id * A ) -> ( id * id )