问题:给定一个文本文件作为输入,任务是计算文件中给定单词的出现频率。
解释:
Lex是一个生成词法分析器的计算机程序,由Mike Lesk和Eric Schmidt编写。 Lex读取指定词法分析器的输入流,并输出以C编程语言实现词法分析器的源代码。
方法:
众所周知, yytext拥有当前匹配令牌的值,我们可以将其与要计数其频率的单词进行比较。如果yytext的值与给定的单词相同,则增加count变量。
输入文件: input.txt

下面是上述方法的实现:
/* LEX code to count the frequency
of the given word in a file */
/* Definition section */
/* variable word indicates the word
whose frequency is to be count */
/* variable count is used to store the
frequency of the given word */
%{
#include
#include
char word [] = "geeks";
int count = 0;
%}
/* Rule Section */
/* Rule 1 compares the matched token with the
word to count and increments the count variable
on successful match */
/* Rule 2 matches everything other than string
(consists of albhabets only ) and do nothing */
%%
[a-zA-Z]+ { if(strcmp(yytext, word)==0)
count++; }
. ;
%%
int yywrap()
{
return 1;
}
/* code section */
int main()
{
extern FILE *yyin, *yyout;
/* open the input file
in read mode */
yyin=fopen("input.txt", "r");
yylex();
printf("%d", count);
}
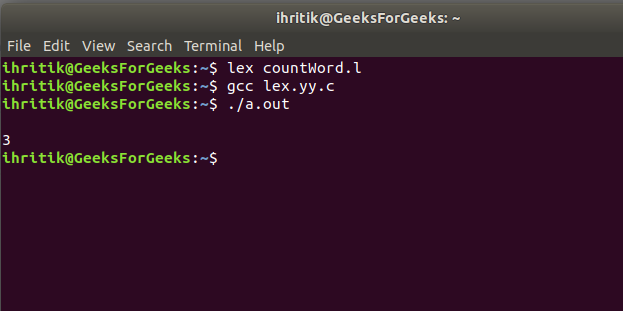
输出: