Python – 从 YouTube 下载字幕
Python提供了大量 API 供开发人员选择。 Google 提供的每项服务都有一个关联的 API。作为其中之一,YouTube Transcript API 使用起来非常简单,提供了各种功能。
在本文中,我们将学习如何从 YouTube 视频下载字幕。字幕可以由 YouTube 自动生成,也可以由导师手动添加,如果这两种类型都可用,我们也会研究如何获得专门的手动或自动字幕。我们还将探索如何获取特定语言的字幕并将字幕从一种语言翻译成另一种语言。然后我们还将看到如何将成绩单写入文本文件。
youtube_transcript_api:此模块用于从 YouTube 视频中获取字幕/副标题。它可以使用以下方法安装:
pip install youtube-transcript-api # for windows
or
pip3 install youtube-transcript-api # for Linux and MacOs 在开始这个过程之前,我们想解释一下如何获取 YouTube 视频的视频 ID。例如,如果 YouTube 视频具有以下 URL
https://youtu.be/SW14tOda_kI那么这个视频的视频ID就是“ SW14tOda_kI”,即 ?v=之后的所有短语都算作视频 ID。 这对于 YouTube 上的每个视频都是独一无二的。
入门
- 现在我们从基础开始,在第一个代码片段中,我们尝试使用.get_transcript()函数获取视频 ID 的转录。
- 它返回一个字典列表,其中每个字典包含 3 个键值对,第一个是内容,第二个是标题句子/短语开始被说出的时刻,第三个是完整说出句子或短语所需的持续时间(以秒为单位)。
- 第一行基本上导入所需的包,下一行分配一个变量来存储字典列表,最后在第三行打印出变量。
Python3
from youtube_transcript_api import YouTubeTranscriptApi
# assigning srt variable with the list
# of dictonaries obtained by the get_transcript() function
srt = YouTubeTranscriptApi.get_transcript("SW14tOda_kI")
# prints the result
print(srt)Python3
from youtube_transcript_api import YouTubeTranscriptApi
# assigning srt variable with the list of dictonaries
# obtained by the the .get_transcript() function
# and this time it gets only teh subtitles that
# are of english langauge.
srt = YouTubeTranscriptApi.get_transcript("SW14tOda_kI",
languages=['en'])
# prints the result
print(srt)Python3
# importing the module
from youtube_transcript_api import YouTubeTranscriptApi
# retrieve the available transcripts
transcript_list = YouTubeTranscriptApi.list_transcripts('SW14tOda_kI')
# iterate over all available transcripts
for transcript in transcript_list:
# the Transcript object provides metadata
# properties
print(
transcript.video_id,
transcript.language,
transcript.language_code,
# whether it has been manually created or
# generated by YouTube
transcript.is_generated,
# whether this transcript can be translated
# or not
transcript.is_translatable,
# a list of languages the transcript can be
# translated to
transcript.translation_languages,
)
# fetch the actual transcript data
print(transcript.fetch())
# translating the transcript will return another
# transcript object
print(transcript.translate('en').fetch())
# you can also directly filter for the language you are
# looking for, using the transcript list
transcript = transcript_list.find_transcript(['en'])
# or just filter for manually created transcripts
transcript = transcript_list.find_manually_created_transcript(['en'])Python3
# importing modules
from youtube_transcript_api import YouTubeTranscriptApi
# using the srt variable with the list of dictonaries
# obtained by the the .get_transcript() function
srt = YouTubeTranscriptApi.get_transcript("SW14tOda_kI")
# creating or overwriting a file "subtitles.txt" with
# the info inside the context manager
with open("subtitles.txt", "w") as f:
# iterating through each element of list srt
for i in srt:
# writing each element of srt on a new line
f.write("{}\n".format(i))输出:
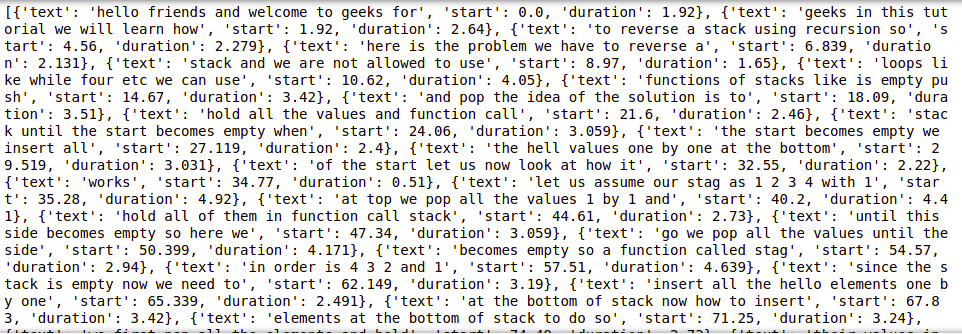
为了获得多个视频的转录,我们可以使用逗号传递它们,如在 YouTubeTranscriptApi.get_transcript(videoid1, Videoid2, ....) 中,在这种情况下,我们将有一个列表列表并在每个内部列表中获得一个字典。
获取特定语言的成绩单
现在,如果我们想要获取特定语言的成绩单,我们可以将语言作为参数提及。在下一个代码片段中,我们的目标是做同样的事情。所有代码和工作都与前面的示例相同,不同之处在于这次它将只获取英文成绩单并忽略字幕(如果存在)。
蟒蛇3
from youtube_transcript_api import YouTubeTranscriptApi
# assigning srt variable with the list of dictonaries
# obtained by the the .get_transcript() function
# and this time it gets only teh subtitles that
# are of english langauge.
srt = YouTubeTranscriptApi.get_transcript("SW14tOda_kI",
languages=['en'])
# prints the result
print(srt)
输出:
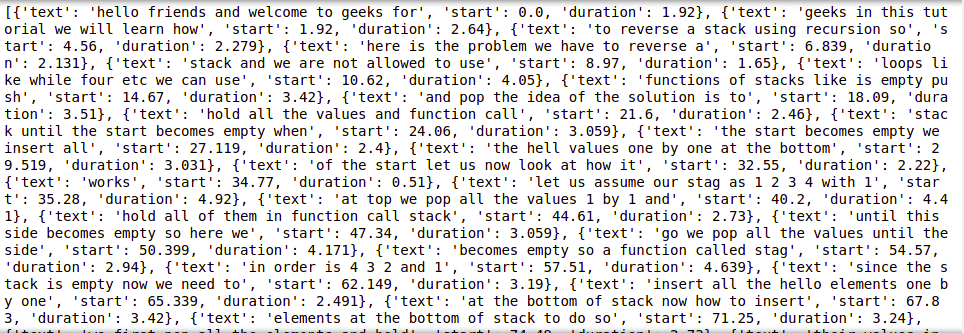
由于我们在此示例中考虑的视频只有英文字幕,因此两个示例都给了我们相同的答案。
获取所有成绩单的列表
- 现在要获取视频的所有转录本列表,我们可以使用.list_transcripts()函数。此函数返回视频可用的所有语言的所有转录本。它返回可迭代的 TranscriptList 对象,并提供过滤特定语言和类型的转录列表的方法。
- 接下来,我们使用函数从获得的元数据中获取一些关于转录本的数据。
- script.video_id返回给我们视频的视频 ID
- 成绩单.language返回我们成绩单的语言
- 成绩单.language_code返回成绩单的语言代码,例如,“en”代表英语等。
- script.is_generated告诉我们它是手动创建的还是由 YouTube 生成的
- 转录本.is_translatable 告诉这个转录本是否可以翻译
- 转录本.translation_languages为我们提供了转录本可以翻译成的语言列表。
- 然后我们使用.fetch()函数来获取实际的成绩单。
- 然后我们还展示了如何使用.translate()函数将字幕从一种语言转换/翻译成另一种语言,如果它完全可以翻译(因为我们只有这种语言的英文字幕,在这种情况下可能不明显,但是这个如果视频中有不止一种语言的文字记录,翻译将非常有用)。
- 下一行我们有.find_transcript()函数,它可以帮助我们获取我们想要的视频的实际转录本以及元数据。
- 最后,我们使用.find_manually_created_transcript()函数专门查找手动下标,与此类似,我们有.find_generated_transcript() ,我们在此示例中没有使用它,因为没有生成的字幕,我们这里只有手动字幕。
蟒蛇3
# importing the module
from youtube_transcript_api import YouTubeTranscriptApi
# retrieve the available transcripts
transcript_list = YouTubeTranscriptApi.list_transcripts('SW14tOda_kI')
# iterate over all available transcripts
for transcript in transcript_list:
# the Transcript object provides metadata
# properties
print(
transcript.video_id,
transcript.language,
transcript.language_code,
# whether it has been manually created or
# generated by YouTube
transcript.is_generated,
# whether this transcript can be translated
# or not
transcript.is_translatable,
# a list of languages the transcript can be
# translated to
transcript.translation_languages,
)
# fetch the actual transcript data
print(transcript.fetch())
# translating the transcript will return another
# transcript object
print(transcript.translate('en').fetch())
# you can also directly filter for the language you are
# looking for, using the transcript list
transcript = transcript_list.find_transcript(['en'])
# or just filter for manually created transcripts
transcript = transcript_list.find_manually_created_transcript(['en'])
输出:

将字幕写入文本文件
现在我们将看到如何在文本文件中编写 YouTube 视频的字幕。首先,我们将导入模块,然后使用 .get_transcript()函数获取转录本或标题并将其存储到变量中。然后我们将使用Python的内置文件阅读器。该行使用上下文管理器,因此我们无需担心在工作完成后关闭文件。我们以写入模式打开一个名为subtitles.txt的文件,然后在其中遍历列表的每个元素,然后将其写入文件。代码如下:
蟒蛇3
# importing modules
from youtube_transcript_api import YouTubeTranscriptApi
# using the srt variable with the list of dictonaries
# obtained by the the .get_transcript() function
srt = YouTubeTranscriptApi.get_transcript("SW14tOda_kI")
# creating or overwriting a file "subtitles.txt" with
# the info inside the context manager
with open("subtitles.txt", "w") as f:
# iterating through each element of list srt
for i in srt:
# writing each element of srt on a new line
f.write("{}\n".format(i))
输出:
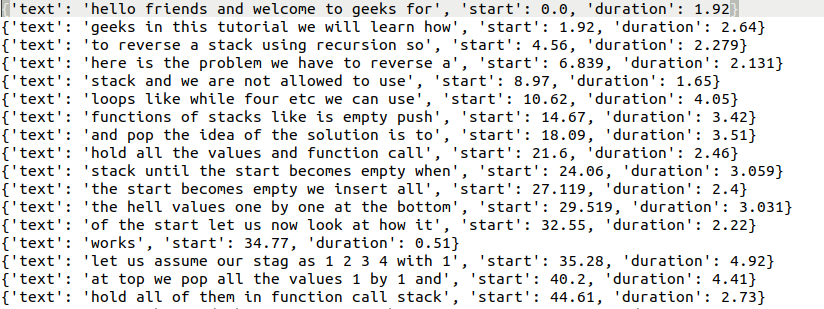
如果您只是在上下文管理器中输入文件名,则该文件将在与 .py 文件相同的目录中创建,要在不同的位置创建/保存它,我们需要为其提供绝对或相对路径。此外,该程序可能会为标题中的未知字符生成错误。但是,字幕文件将使用已知字符创建。