Pandas – Groupby 多个值和绘图结果
在本文中,我们将学习如何对多个值进行分组并一次性绘制结果。在这里,我们从 seaborn 库中获取数据集的“exercise.csv”文件,然后形成不同的 groupby 数据并将结果可视化。
对于此过程,所需的步骤如下:
- 为数据及其可视化导入库。
- 创建和导入具有多列的数据。
- 通过对多个值进行分组来形成一个 grouby 对象。
- 可视化分组数据。
下面是一些示例的实现:
示例 1:
在此示例中,我们从 seaborn 库中获取数据集的“exercise.csv”文件,然后根据“时间”列将“脉冲”和“饮食”两列组合在一起,形成 groupby 数据,最后可视化结果。
Python3
# importing packages
import seaborn
# load dataset and view
data = seaborn.load_dataset('exercise')
print(data)
# multiple groupby (pulse and diet both)
df = data.groupby(['pulse', 'diet']).count()['time']
print(df)
# plot the result
df.plot()
plt.xticks(rotation=45)
plt.show()Python3
# importing packages
import seaborn
# load dataset
data = seaborn.load_dataset('exercise')
# multiple groupby (pulse and diet both)
df = data.groupby(['pulse', 'diet']).count()['time']
# plot the result
df.unstack().plot()
plt.xticks(rotation=45)
plt.show()Python3
# importing packages
import seaborn
# load dataset and view
data = seaborn.load_dataset('exercise')
print(data)
# multiple groupby (pulse, diet and time)
df = data.groupby(['pulse', 'diet', 'time']).count()['kind']
print(df)
# plot the result
df.plot()
plt.xticks(rotation=30)
plt.show()Python3
# importing packages
import seaborn
# load dataset
data = seaborn.load_dataset('exercise')
# multiple groupby (pulse, diet, and time)
df = data.groupby(['pulse', 'diet', 'time']).count()['kind']
# plot the result
df.unsatck().plot()
plt.xticks(rotation=30)
plt.show()输出 :
Unnamed: 0 id diet pulse time kind
0 0 1 low fat 85 1 min rest
1 1 1 low fat 85 15 min rest
2 2 1 low fat 88 30 min rest
3 3 2 low fat 90 1 min rest
4 4 2 low fat 92 15 min rest
.. ... .. ... ... ... ...
85 85 29 no fat 135 15 min running
86 86 29 no fat 130 30 min running
87 87 30 no fat 99 1 min running
88 88 30 no fat 111 15 min running
89 89 30 no fat 150 30 min running
[90 rows x 6 columns]
pulse diet
80 no fat NaN
low fat 1.0
82 no fat NaN
low fat 1.0
83 no fat 2.0
...
140 low fat NaN
143 no fat 1.0
low fat NaN
150 no fat 1.0
low fat NaN
Name: time, Length: 78, dtype: float64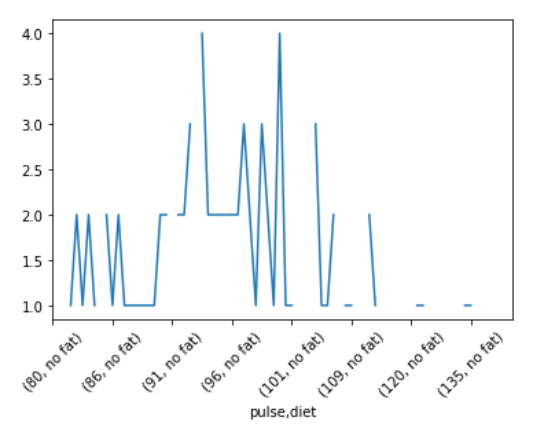
示例 2:本示例是对上述示例的修改,以便更好地可视化。
Python3
# importing packages
import seaborn
# load dataset
data = seaborn.load_dataset('exercise')
# multiple groupby (pulse and diet both)
df = data.groupby(['pulse', 'diet']).count()['time']
# plot the result
df.unstack().plot()
plt.xticks(rotation=45)
plt.show()
输出 :

示例 3:
在此示例中,我们从 seaborn 库中获取数据集的“exercise.csv”文件,然后在“种类”列的基础上将“脉冲”、“饮食”和“时间”三列组合在一起,形成 groupby 数据。最后可视化结果。
Python3
# importing packages
import seaborn
# load dataset and view
data = seaborn.load_dataset('exercise')
print(data)
# multiple groupby (pulse, diet and time)
df = data.groupby(['pulse', 'diet', 'time']).count()['kind']
print(df)
# plot the result
df.plot()
plt.xticks(rotation=30)
plt.show()
输出 :
Unnamed: 0 id diet pulse time kind
0 0 1 low fat 85 1 min rest
1 1 1 low fat 85 15 min rest
2 2 1 low fat 88 30 min rest
3 3 2 low fat 90 1 min rest
4 4 2 low fat 92 15 min rest
.. ... .. ... ... ... ...
85 85 29 no fat 135 15 min running
86 86 29 no fat 130 30 min running
87 87 30 no fat 99 1 min running
88 88 30 no fat 111 15 min running
89 89 30 no fat 150 30 min running
[90 rows x 6 columns]
pulse diet time
80 no fat 1 min NaN
15 min NaN
30 min NaN
low fat 1 min 1.0
15 min NaN
...
150 no fat 15 min NaN
30 min 1.0
low fat 1 min NaN
15 min NaN
30 min NaN
Name: kind, Length: 234, dtype: float64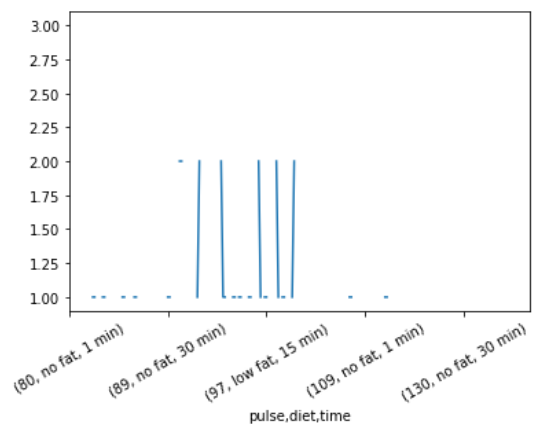
例子4:这个例子是对上面例子的修改,为了更好的可视化。
Python3
# importing packages
import seaborn
# load dataset
data = seaborn.load_dataset('exercise')
# multiple groupby (pulse, diet, and time)
df = data.groupby(['pulse', 'diet', 'time']).count()['kind']
# plot the result
df.unsatck().plot()
plt.xticks(rotation=30)
plt.show()
输出 :
