数据挖掘中的主动学习
主动学习是一种迭代类型的监督学习,如果数据高度可用,但类标签稀缺或获取成本高,则通常首选这种学习方法。学习算法查询标签。使用主动学习来学习概念的元组数量远小于典型监督学习所需的数量。仅在主动学习中使用一些标记实例即可开发出高精度模型。与其他学习方法相比,主动学习的成本较低。
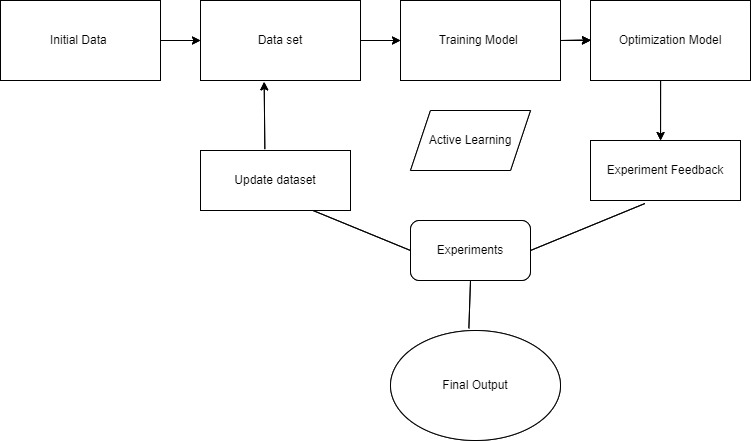
主动学习在数据训练过程中获得了很高的准确性,并且训练模型所需的时间更少。主动学习仅支持标记的训练集。为主动学习数据开发了几种策略。主动学习的有效策略之一是基于池的方法。
主动学习中基于池的方法示例:
让我们将D视为数据集。标记数据集L是D的子集。 U是数据集D 的未标记数据。L是主动学习器使用L开始训练的初始训练集。对未标记数据U应用查询函数以选择一个或多个数据样本,并从甲骨文。新标记的数据被添加到之前的训练集L中,主动学习器使用标准监督算法学习标记样本的特征。通过从训练和测试集中构建学习曲线并绘制所构建模型的准确度图来评估主动学习算法。
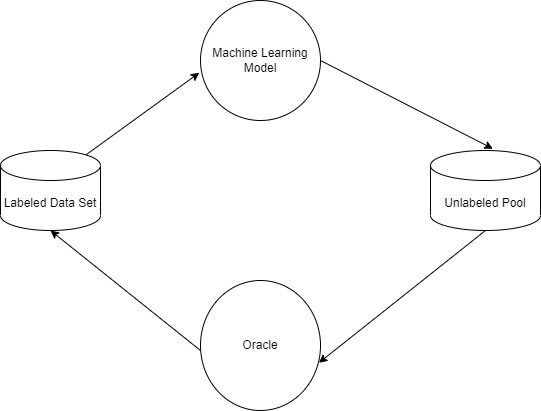
主动学习的主要任务是选择要查询的数据元组。提出了许多算法和方法来选择数据元组。不确定性抽样是最常见的方法,主动学习者选择查询最不确定如何标记的元组。还有一些其他策略可以减少版本空间,以便找出与标记的训练元组一致的所有假设的子集。有必要在训练元组中进行错误检测以去除数据的噪声。
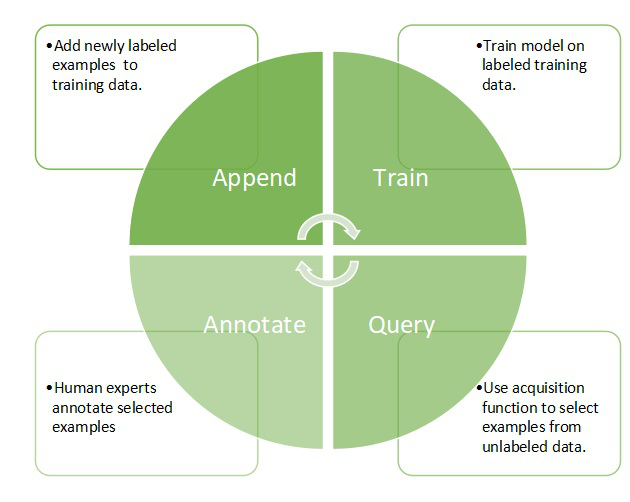
错误检测后选择的元组通过减少 U 上的预期熵来确保最大程度地减少不正确的预测。但是这种方法需要更多的计算操作。