机器学习中的正则化
先决条件:梯度下降
过拟合是当机器学习模型受限于训练集并且无法在看不见的数据上表现良好时发生的一种现象。

正则化是一种通过在给定的训练集上适当地拟合函数来减少错误并避免过度拟合的技术。
常用的正则化技术有:
- L1 正则化
- L2 正则化
- Dropout 正则化
本文重点介绍 L1 和 L2 正则化。
使用L1 正则化技术的回归模型称为LASSO(Least Absolute Shrinkage and Selection Operator)回归。
使用L2 正则化技术的回归模型称为岭回归。
套索回归将系数的“幅度的绝对值”作为惩罚项添加到损失函数(L) 中。

岭回归将系数的“平方大小”作为损失函数(L)的惩罚项。

请注意,在正则化期间,输出函数(y_hat) 不会改变。变化仅在损失函数。
输出函数:

正则化前的损失函数:

正则化后的损失函数:

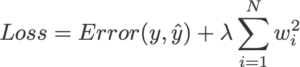
我们将 Logistic 回归中的损失函数定义为:
L(y_hat,y) = y log y_hat + (1 - y)log(1 - y_hat)
没有正则化的损失函数:
L = y log (wx + b) + (1 - y)log(1 - (wx + b)) 假设数据过度拟合上述函数。
L1 正则化的损失函数:
L = y log (wx + b) + (1 - y)log(1 - (wx + b)) + lambda*||w||1 L2 正则化的损失函数:
L = y log (wx + b) + (1 - y)log(1 - (wx + b)) + lambda*||w||22 lambda是一个超参数,称为正则化常数,它大于零。
lambda > 0